chainsawriot
Home | About | ArchiveAdvent of emacs #12: How I do version control in emacs
I can’t believe I am now in the mid-point. I thought I would tap out on maybe day 3.
Git is the undisputed champion of version control software. But git the command line program is actually a monolithic application that is difficult to use and scares away many newbies. Similar to the discoverability issue of emacs I talked about on day 2, git also has the discoverability problem and many users resort to cheatsheets and tutorials. I actually have written about git in the past. An obvious symptom of this problem is the wide spread .DS_Store files pushed to Github 1. It is caused by the uninformed usage of sweeping git command such as git add . to stage all changed files (including hidden files such as .DS_Store), which even Github teaches new users to do so.
Previously, I also said that there is no shame not to use the command line. In 99% of the situation, I don’t use the command line version of git. Even when I convince people in my milieu to use git, I teach them to use the git tab of RStudio.
For me, of course, I use —in my humble opinion— the killer app of emacs: magit. And actually, I made no customization to magit and the out-of-the-box user experience is wonderful already.
(use-package magit
:init
(global-set-key (kbd "C-c g") 'magit-status)
)
Magit
And yes, magit is a “dired-like” tool. And because of that, my first impression was… meh… (“But that can well be my prejudice.”™) But after really digging deep into magit, I can understand the appeal of it. I believe the most important power of magit can be felt when doing interactive rebase. And this is a technique that users who consider themselves as intermediate git users should pull off comfortably.
But what is it exactly? Well, I would like to show you a world without it. The following are the initial first few commits of the R package rio.
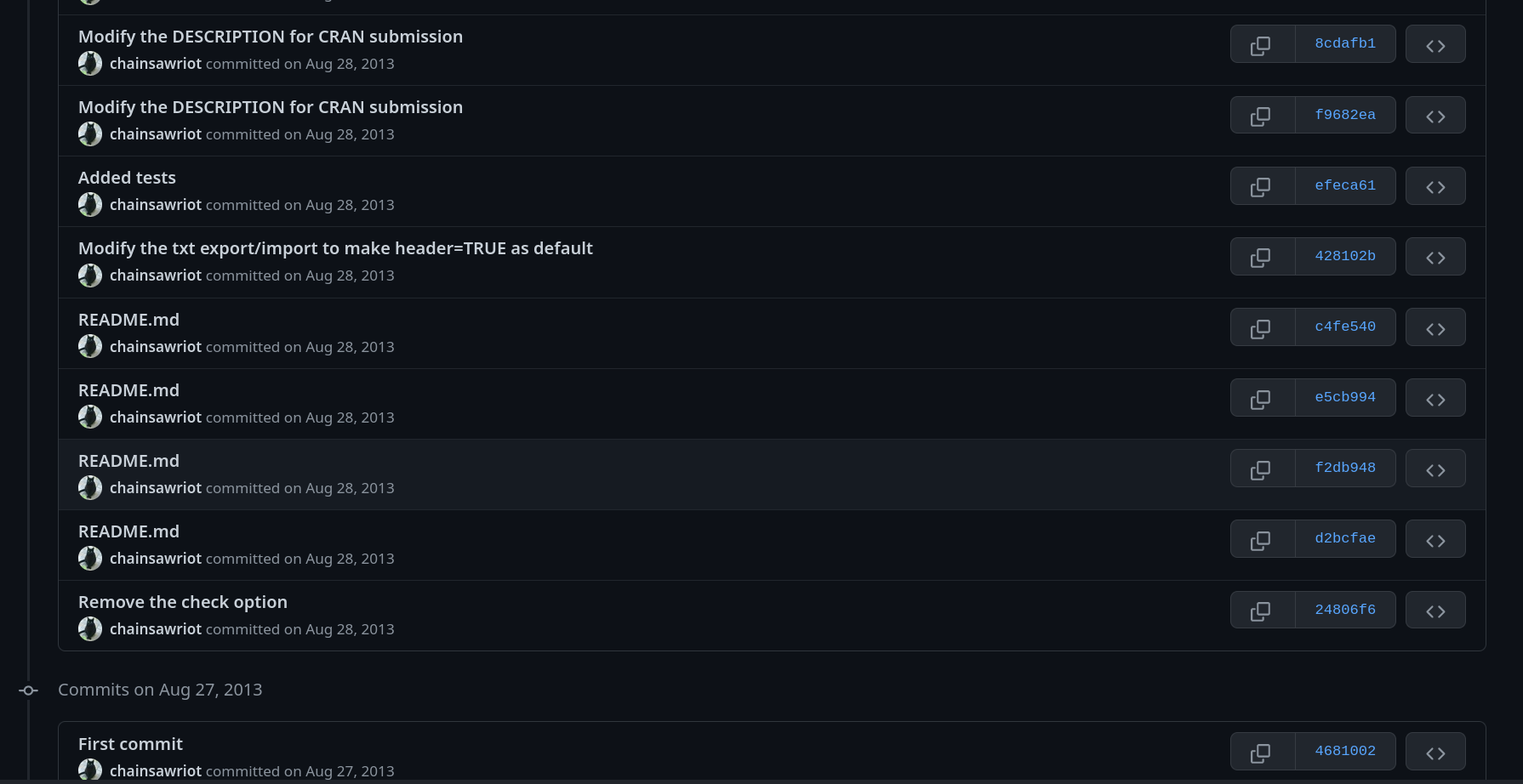
I like to look at these and laugh at them. The main reason for this ridiculous commit history was that I didn’t know how to branch 10 years ago and therefore I worked on the default branch (the “master” or “main” branch. I don’t want to make any assumption, so let’s call it default branch) exclusively. And therefore, there are many useless commits in the commit history. And the problem is these useless commits set in stone and I can probably still be able to laugh at them again in 2033 (or even when humans do not exist anymore in 2133, by the visitors from the outer space. That’s because rio is in Github’s arctic vault).
Branching
There is no reason not to use branch. And I am tell you: I never work on the default branch. I let my team lead to merge my pull request to the default branch. And what I really do with the default branch are two things: 1) Pull the newest commits from the remote default branch to my local default branch (the single key command is “F” in Magit); and 2) create a new branch from the default branch. Punkt. If you start to work this way, you will finally understand version control.
It’s extremely easy to create a new branch. Just press “b” and then “c” (checkout a new branch). Unlike dired’s mysterious approach, features of magit are discoverable with all the on-screen instructions.
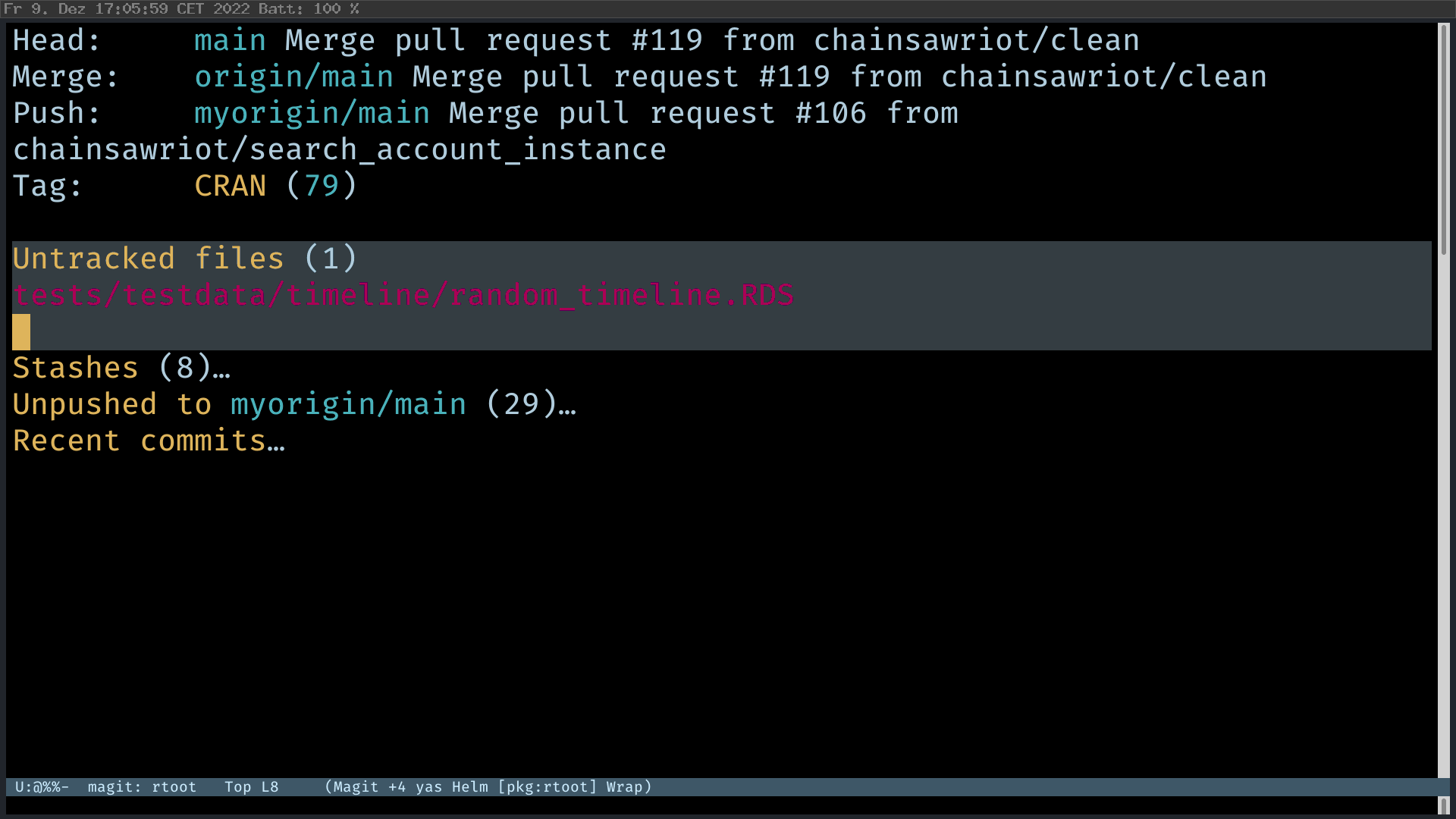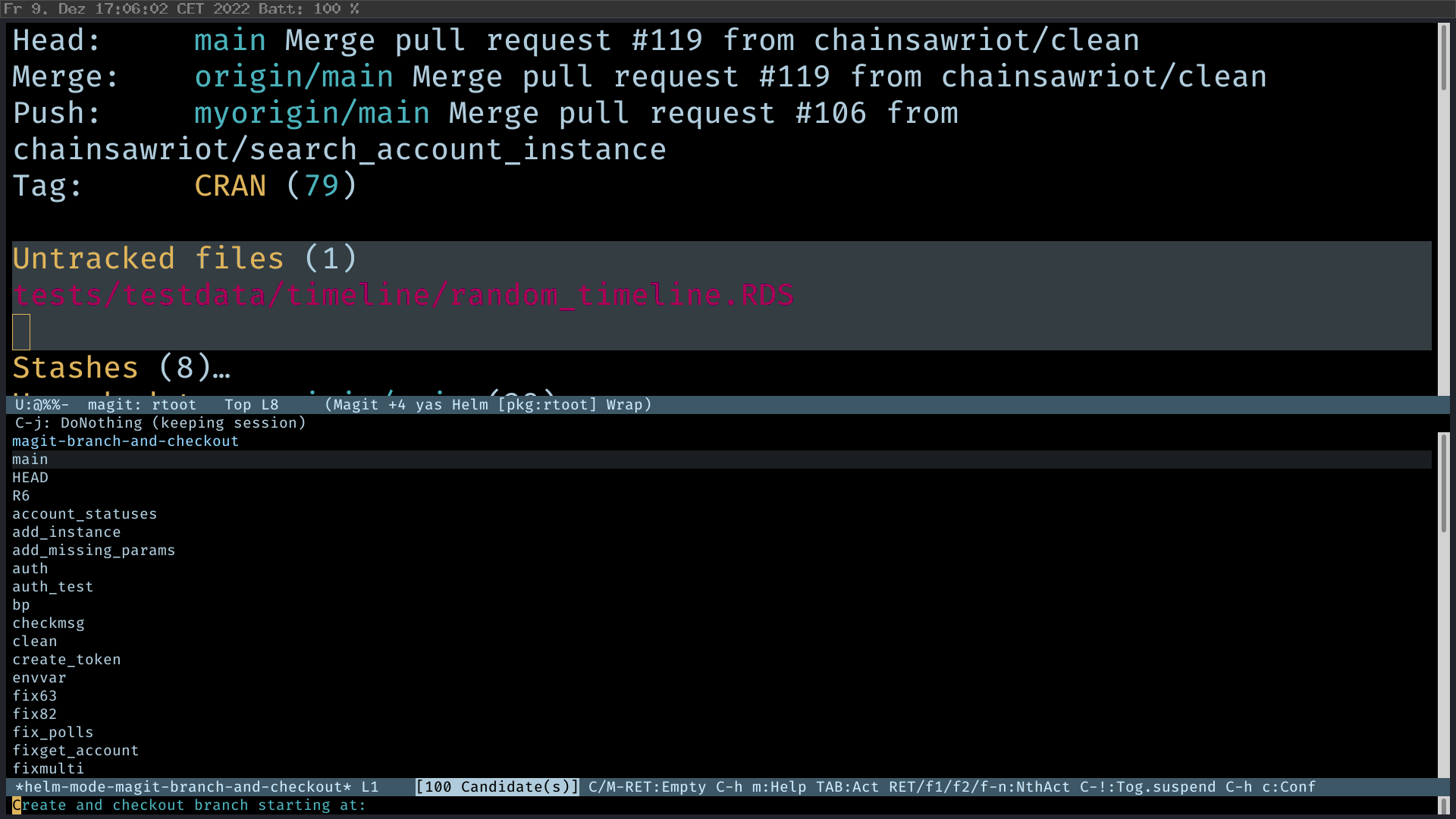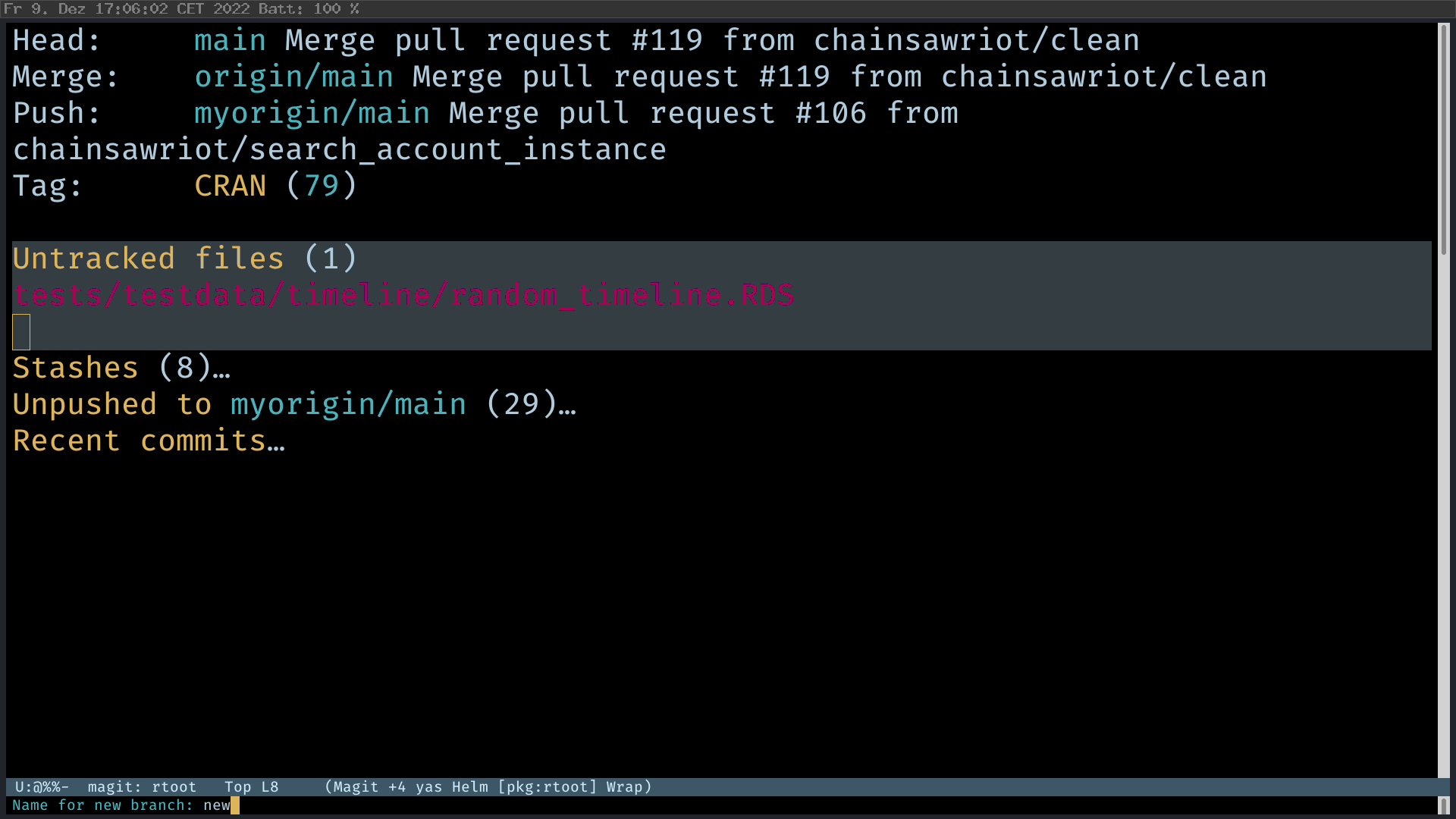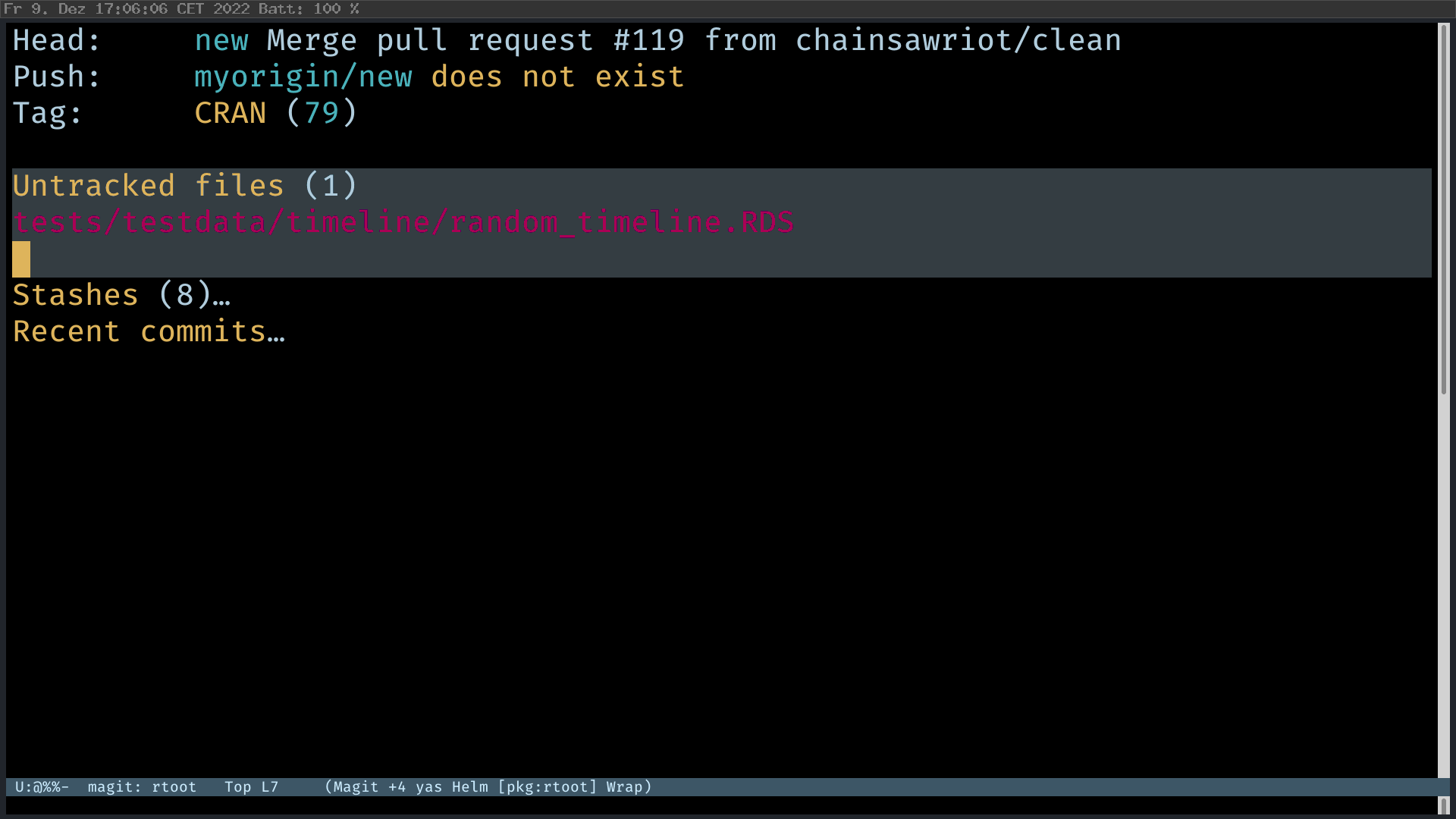
Making Commits
Suppose you have made some changes to a file. Magit will show the change you have made. Press “s” to stage the individual changed file (So that one doesn’t need to use sweeping command such as git add .). And then press “c” to commit. Type the commit message, review the change, C-c C-c. Fertig.
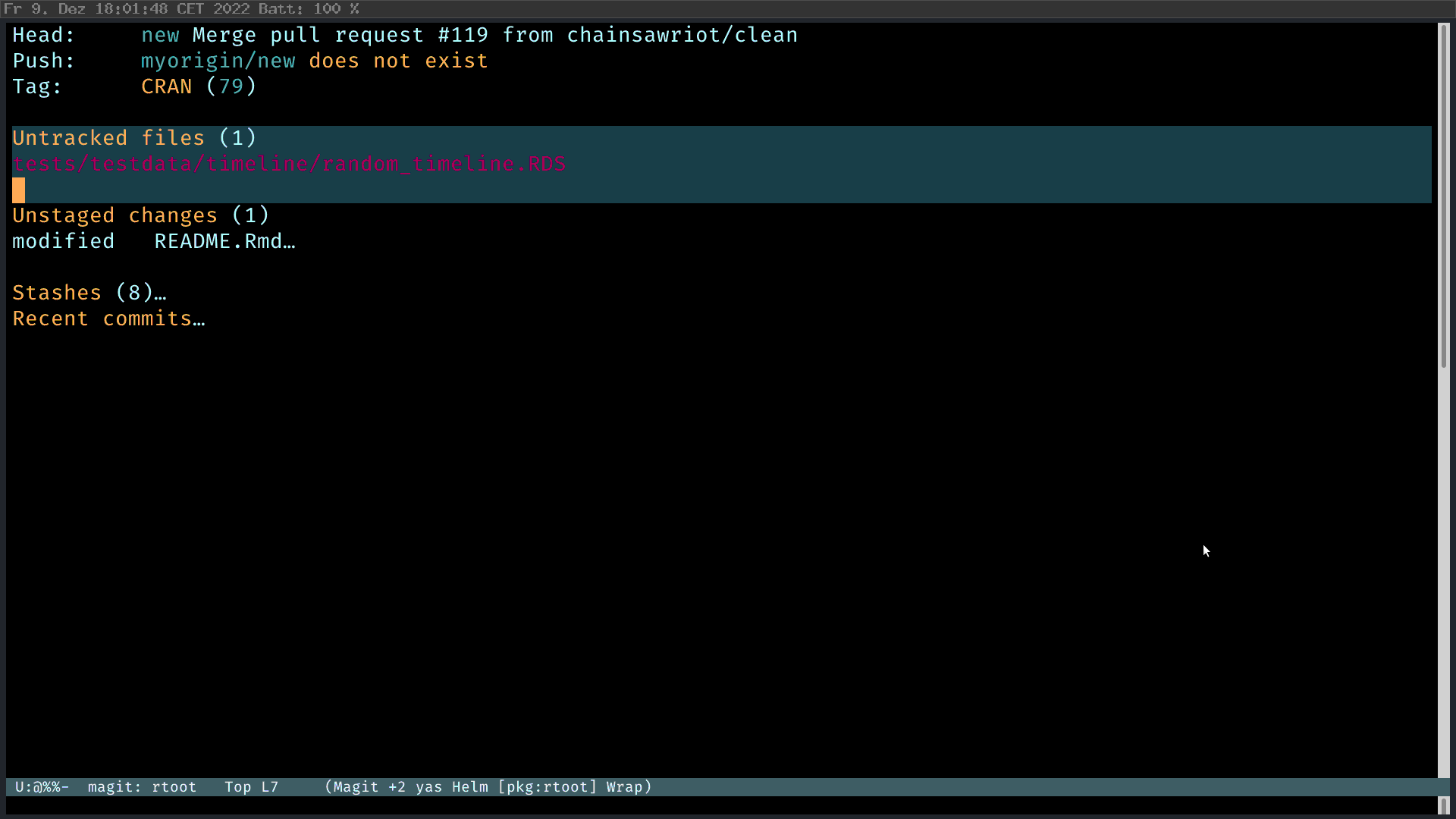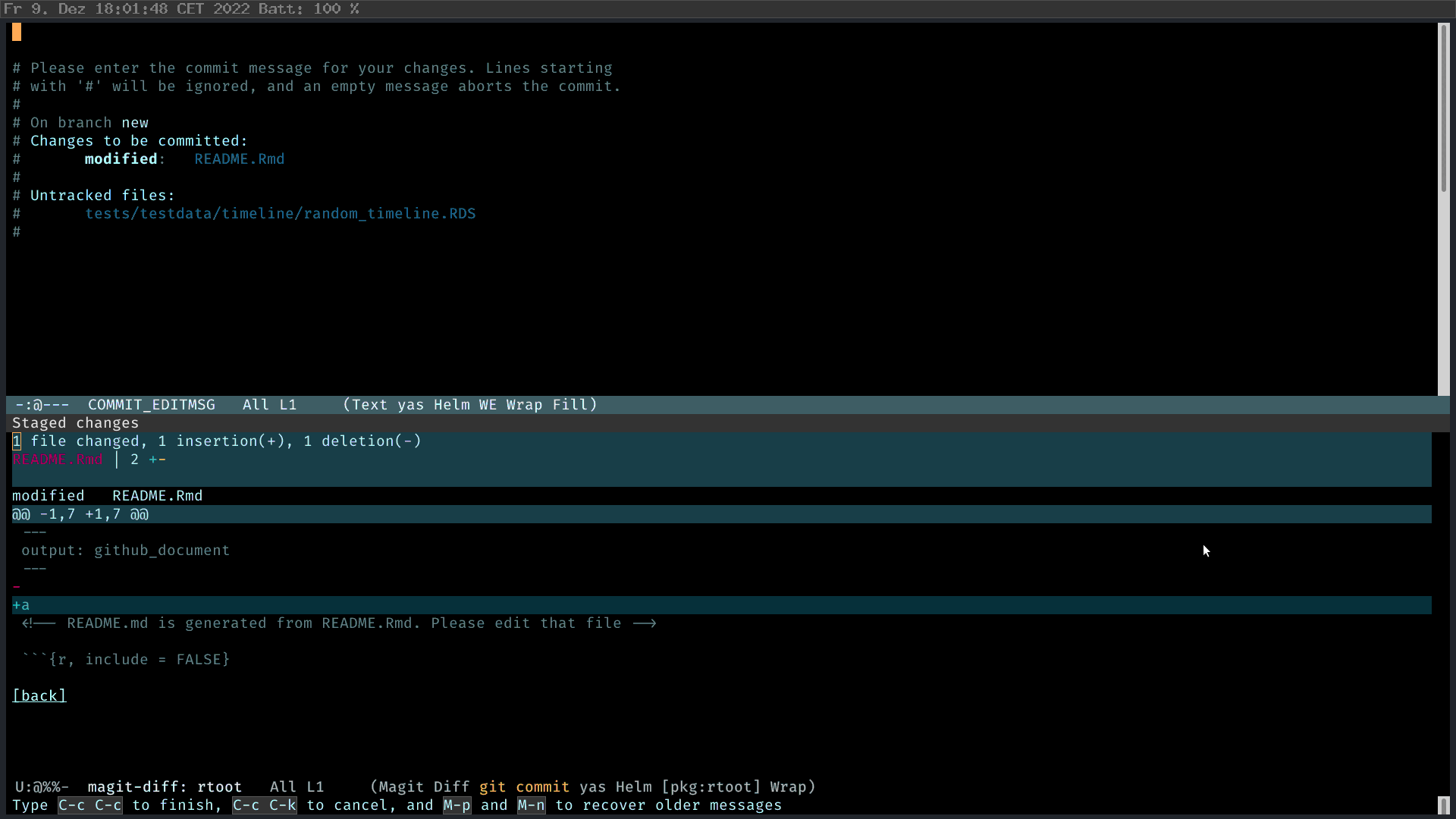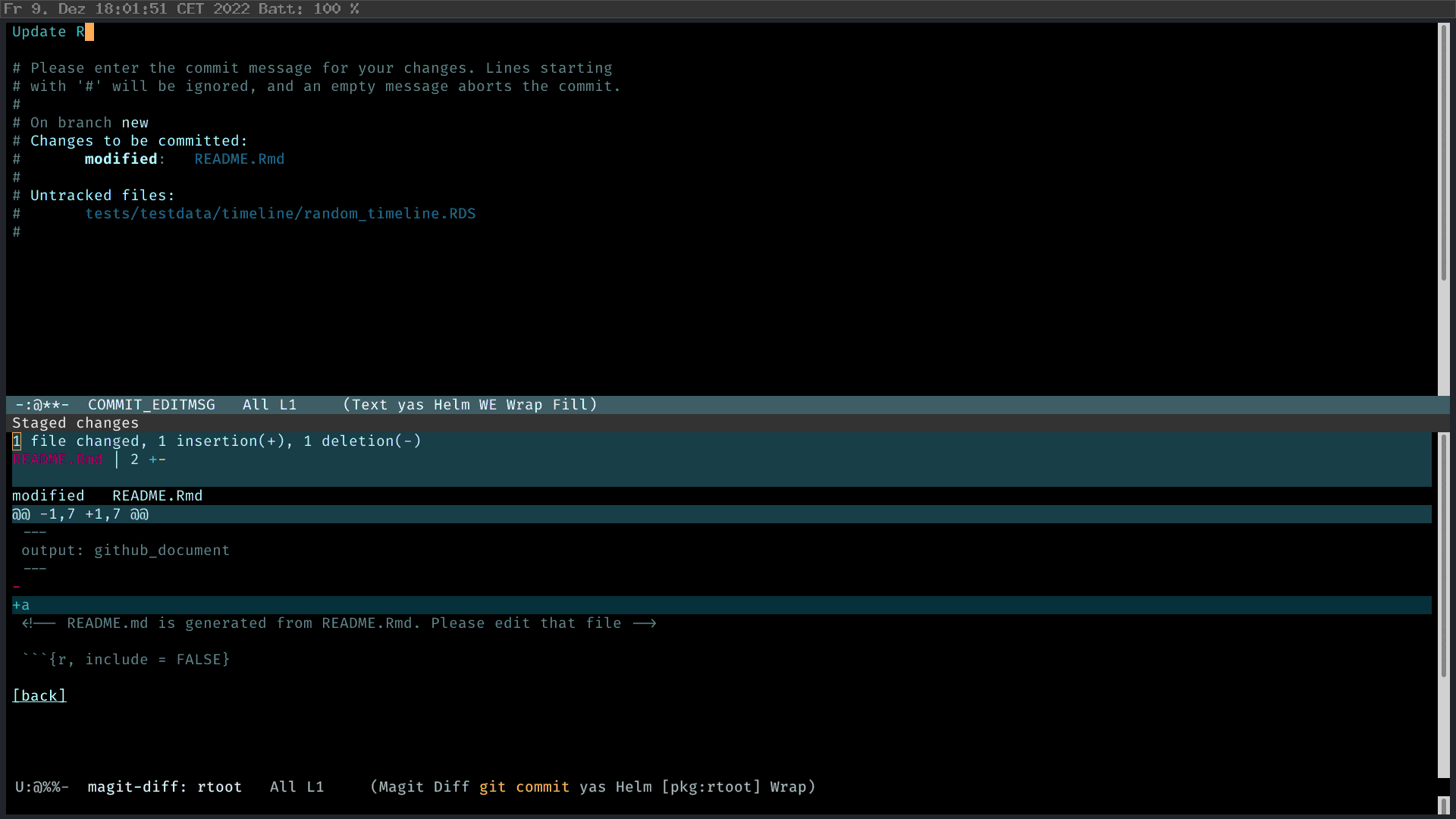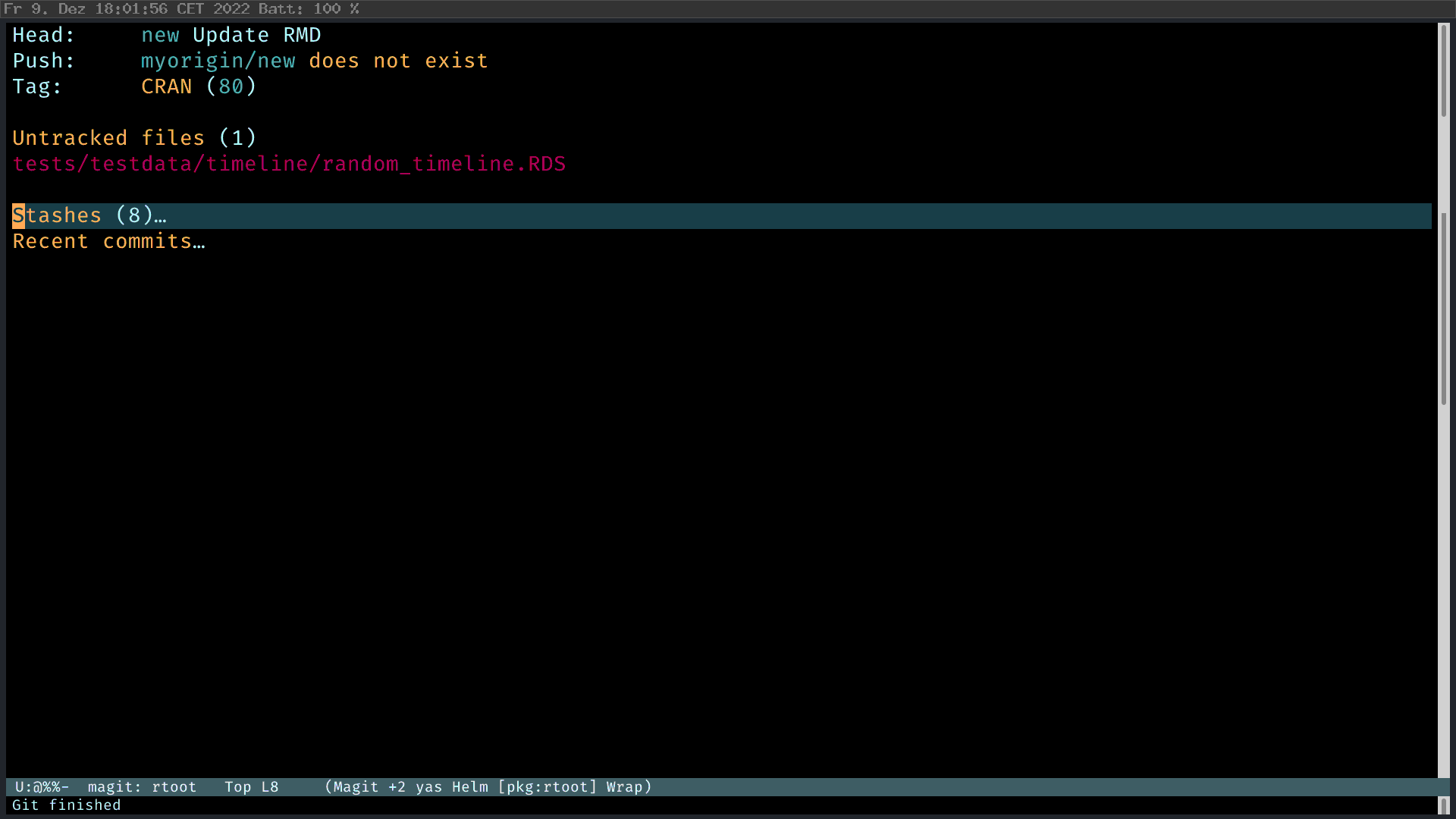
Doing interactive rebase
It is extremely easy to fuck up the commit history with something like this:
In this example, I created a commit to update the README. And then I found that I have fucked up and fixed a typo in the README. And then I really implemented the updated feature. Of course, the fucked up commit should be eliminated. The second problem is that I look very unprofessional to first modify the README and then implement the feature. This is an ideal use case of interactive rebase. To put it simply, interactive rebase is rewriting history. What I want to have, is a change where the feature commit comes first in the commit history; then the change commit about README without fucking up.
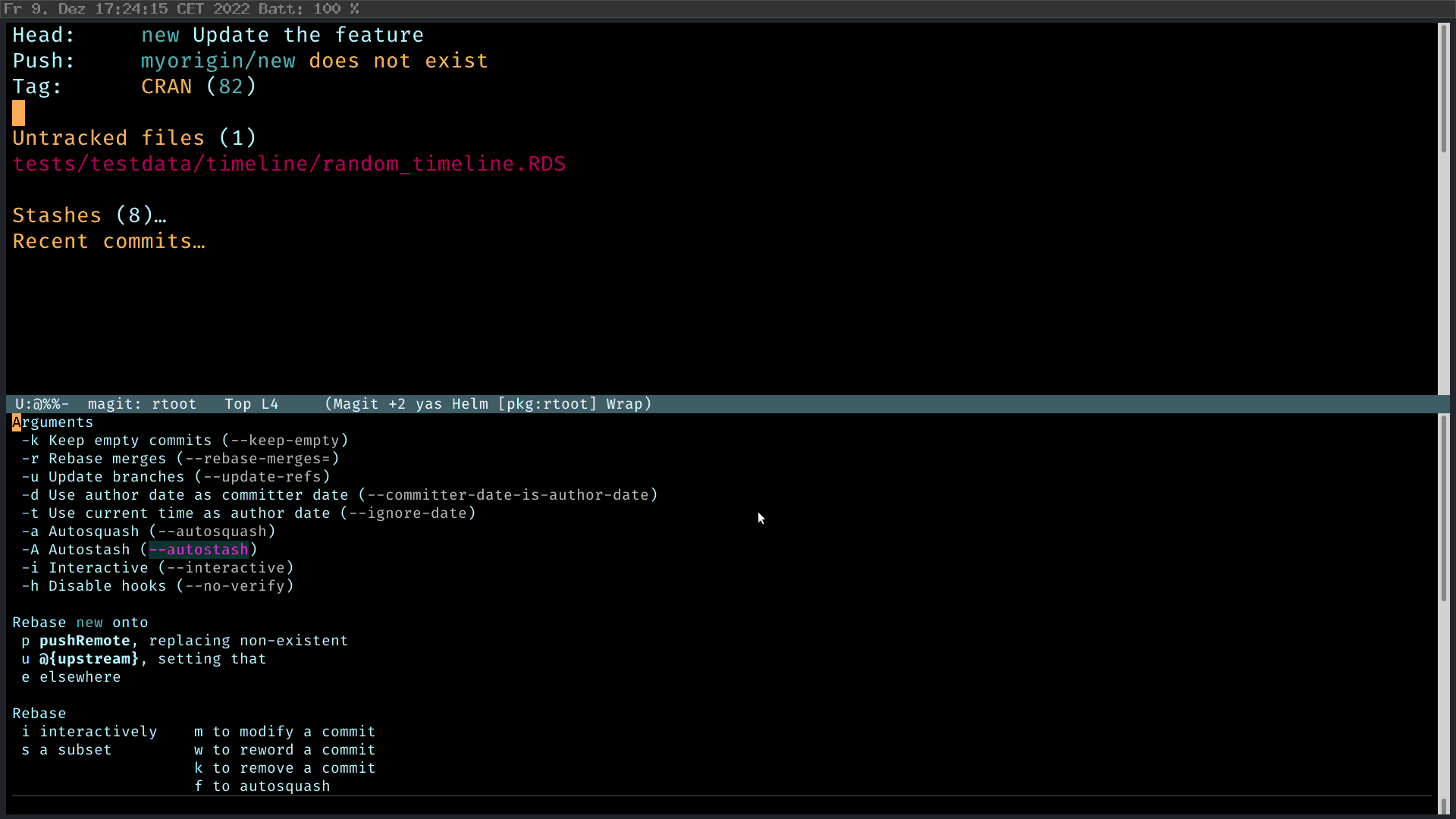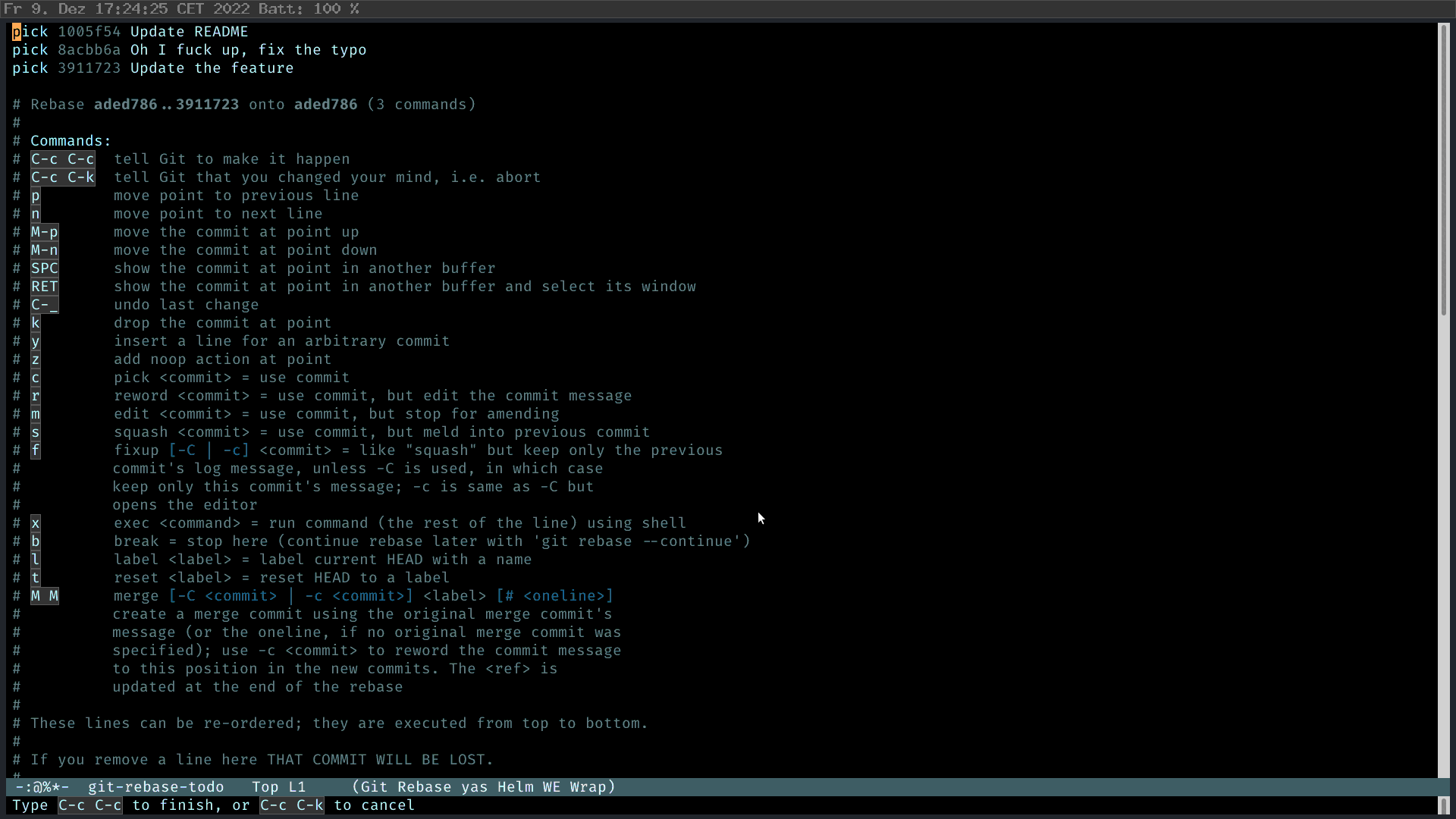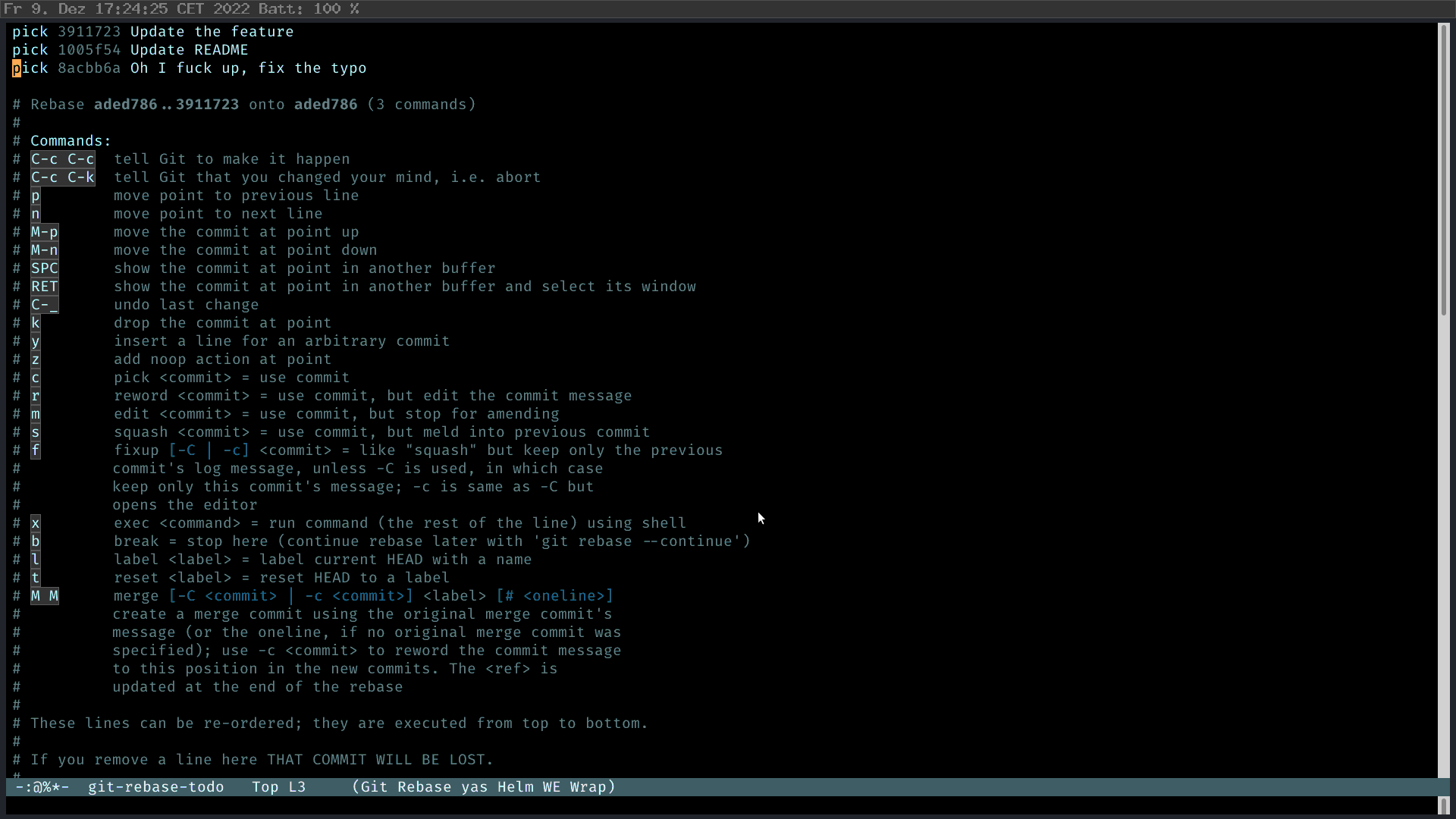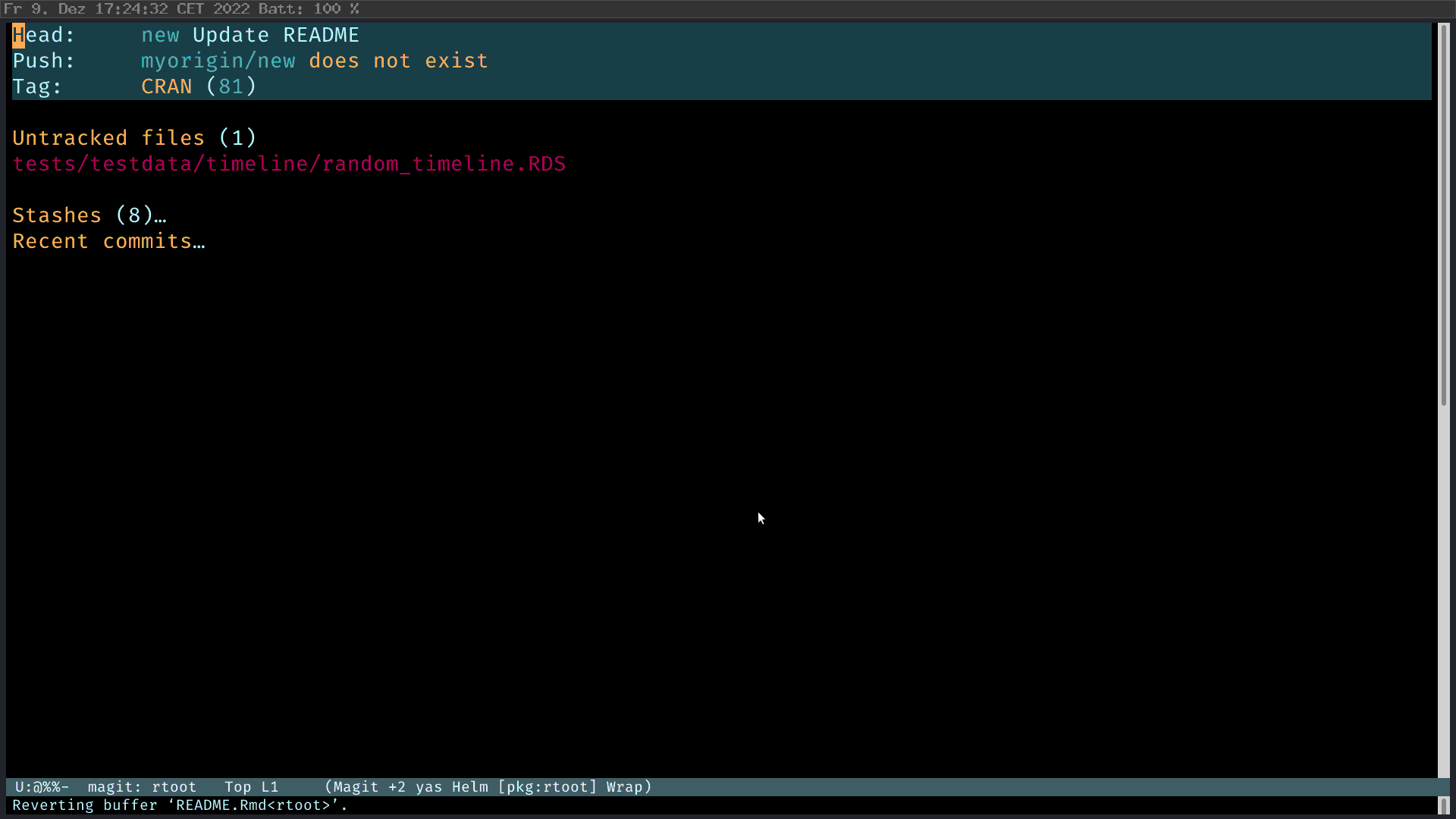
In Magit, I press “r” (rebase), and then “i” (interactive) to start the interactive rebase process. Then I select the commits I want to rebase. Magit is smart enough to tell you what you should do. M-p to move the feature commit up; and then mark the “fuck up” commit as FIXUP 2, C-c C-c. Fertig.
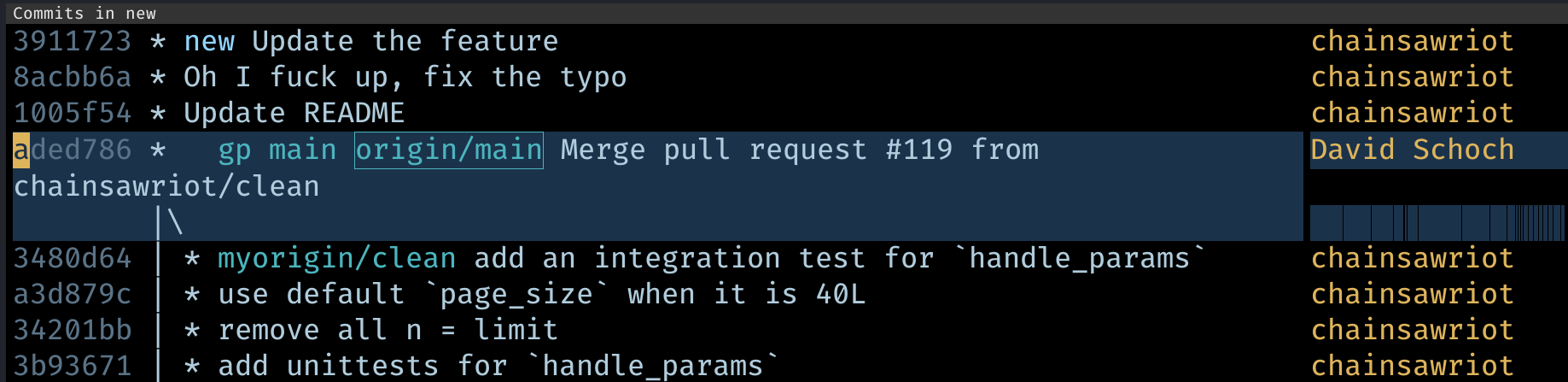
And then I can have a clean commit history like this.
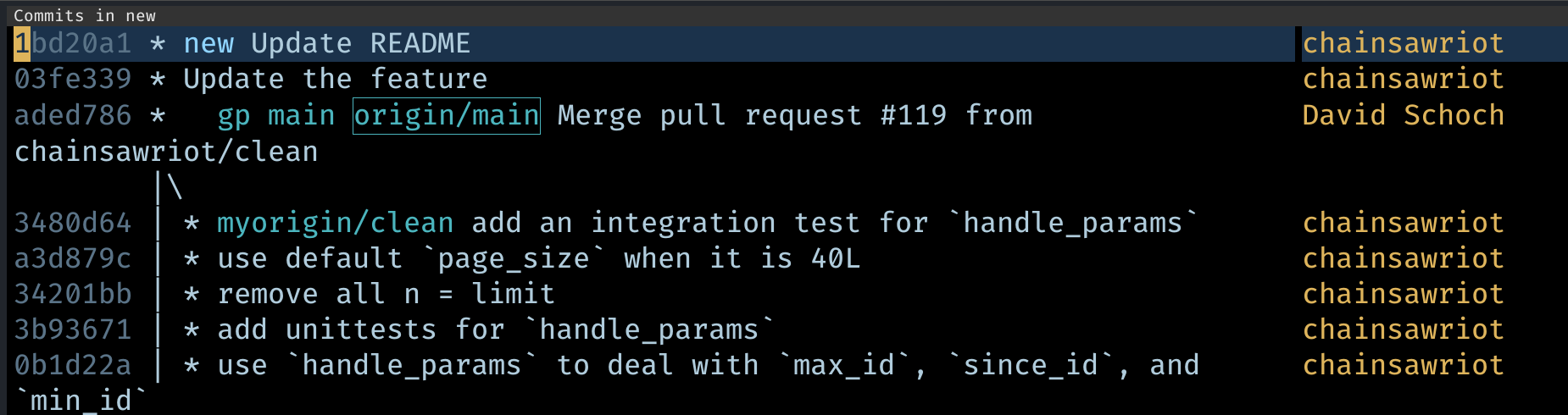
And I can push it to my own remote (press “P”), submit a pull request at the upstream, and my team lead is happy. And I look like a programming Sith, not the n00b making 4 commits just to update the README.
Moving on
In the next 5 days, I will talk about some academic tasks. If you don’t smell like ivory, you probably don’t need to care about the day 13-17. See you again on day 18. If you has a strong ivory body odor, stay.
-
I don’t want to frame this as a Mac problem. ↩
-
Fixup means: I want this commit to be merge with the previous commit. You can also use
squashto merge, but it will keep the commit message in the commit message. There are other labels, such asrewordto rewrite the commit message of a commit,dropto remove a commit,editto edit the content of a commit. So, if you feel like you want to rewrite history, don’t go to work for a startup or buy Twitter. Just do an interactive rebase. ↩