chainsawriot
Home | About | ArchiveFive ways I use Git / Github
Read the previous articles on R package development: software testing, development environment
This is a post about Git and Github. I must write it at the beginning that there is no “correct” way of doing version control. Of course, you can argue a way of being good or bad. But this post is gonna explain how I use Git and Github and why I think these are good ideas. You can dismiss my way as being opinionated. I think it’s gonna be the main purpose of this post: to be the Hegelian antithesis of version control so that you can synthesize an even better way of using version control. This post makes an assumption that you need to use a version control software. I mean: YOU NEED TO USE VERSION CONTROL SOFTWARE. No doubt about it. It could be Git, it could be mercurial, svn, bazaar, BitKepper. But it is probably gonna be Git.
Even though you don’t write R packages, it benefits you a lot by version controlling your analysis scripts, your papers, your book drafts, your thinking, your cooktail recipes, or if you could, yourself.
Empowerment statement
In this post, I am going to explain how I use Git and Github in way that I believe can make me more efficient.
1. Branching
Apart from recording your edits, the most important feature of Git is branching. If you want to be really understanding the need for version control (rather than being a more difficult version of Dropbox or something), you need to know branching. If you want to have a workflow (e.g. git flow), you need to branch.
What is branching, by the way? It is like, at age 37 and you want to make a decision of whether you should stay in your home country or pursue a new career in Germany. You have two choices, stay or go. You want to go but it is going to be the first time for you to work in another country. You may screw up and regret for the rest of your life. How about you freeze the time at age 37 and create a parallel universe that you can try to move to Germany and see how things develop till your 40. If it works, then you merge that parallel universe into your own history. If it doesn’t, then you go back to age 37. Maybe you can then choose to stay. By doing so, you don’t need to regret for the rest of your life.
Don’t you hope that your life can be version controlled? You don’t need to just live your m-life. What’s m? Well, by default in Git, you are working on your m-branch 1. But actually, you can have multiple branches. Next time, if I have a chance to talk about causal inference, I can go back to this.
Back to Git, you need to use branch. From your m-branch, you can branch out to another branch to bravely explore and create experimental features without screwing what you have done. If you like it, merge the new branch to your m-branch. If you don’t like it, switch back to your m-branch. It would be easier to reason Git as a manager of DAG (Directed acyclic graph). If you run this Git command (git log --all --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit) 2, you see something like this:
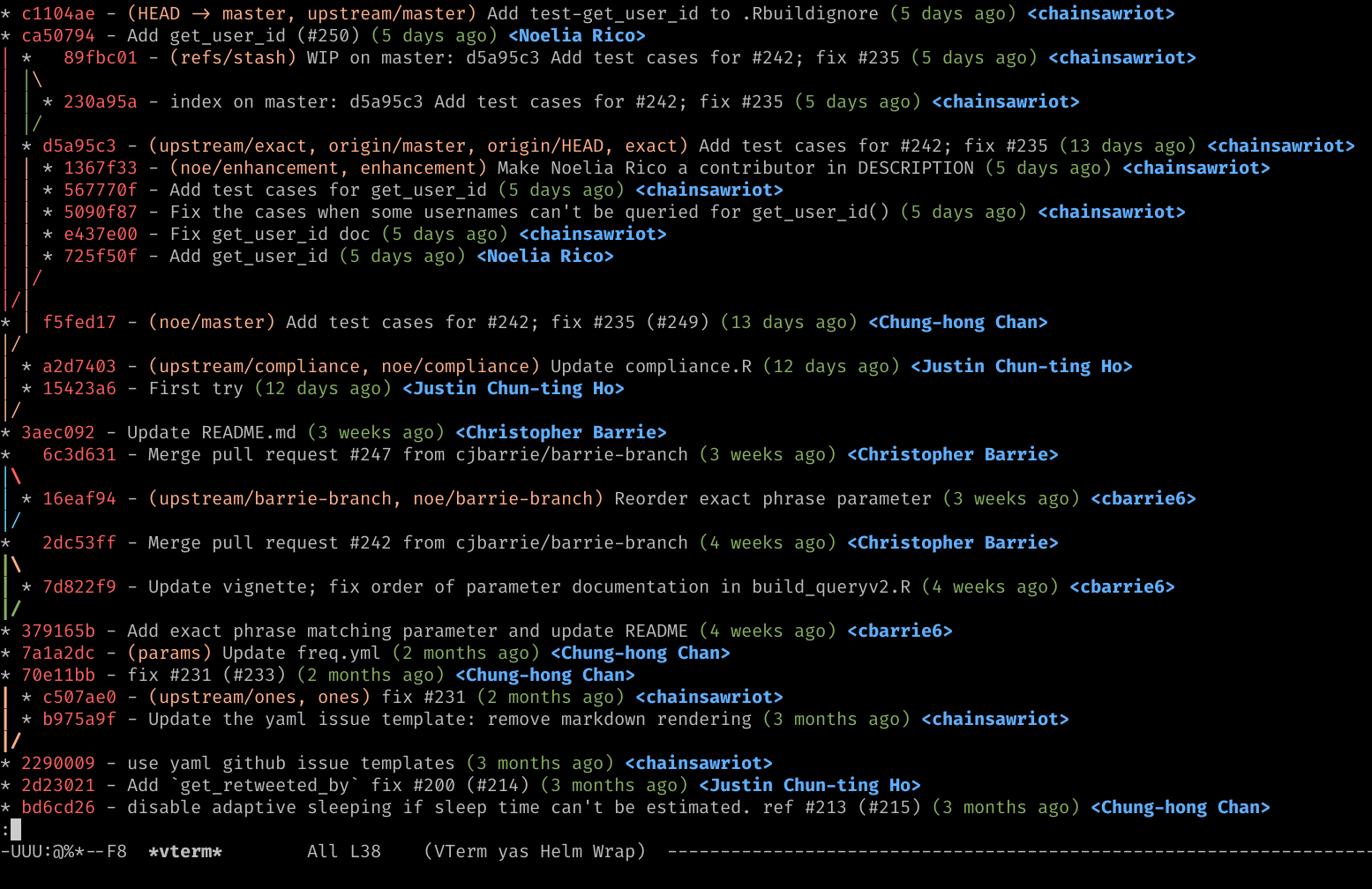
The graph is primitive – just like any command line thing – but it shows a commit as a node (with an asterisk) and there is an edge between each commit. The leftest branch is typically the m-branch. The budding of an edge to the right is an operation of branching; forming an edge back to the left is an operation of merging. It is called a DAG because there is no directed cycles (e.g. you can’t go from A -> B -> C -> A). Once again, learning this is great because it makes learning causal inference easier.
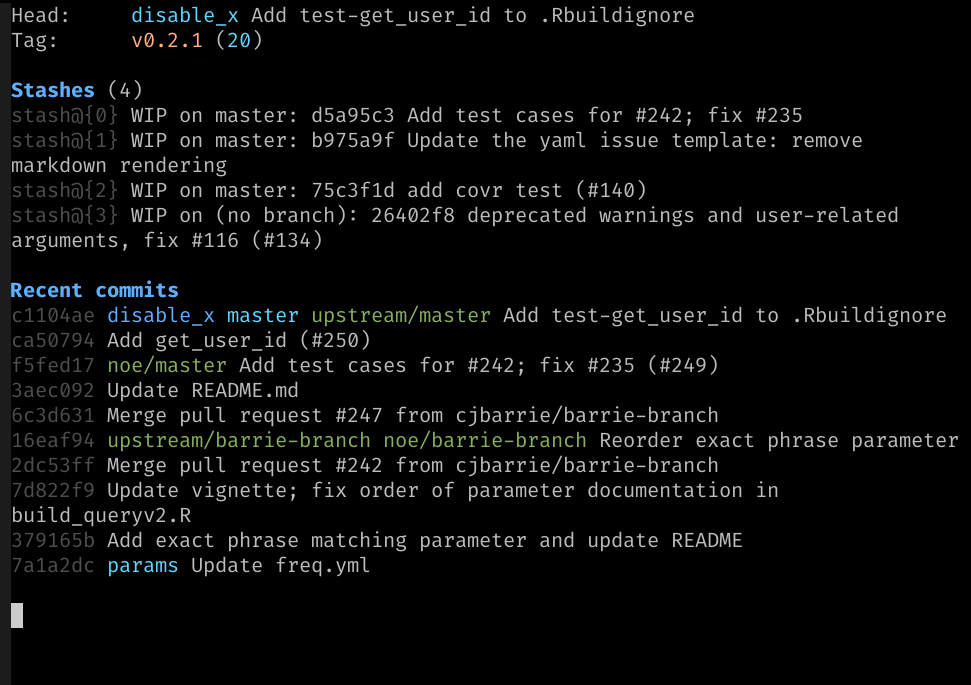
Support you want to create a new branch to create an experimental feature called: “disable_x”. Using the command line client, you can create and switch to a new branch using this command: git checkout -b disable_x. The “-b” flag creates the new branch. At this point, it is also a nice idea to have a better command line environment. If you are using some default command line environment, you see nothing. But, if you are using oh-my-zsh like I am, then you will see something like this:

You can then implement the feature and test it. You can then commit it like you usually do: git commit -am "add the feature disable_x". If you are really happy with the feature, you can then switch back to your m-branch: git checkout master or git checkout main. Finally, git merge disable_x. If you are unhappy with feature, you can then just switch back to your m-branch. Or maybe, you can work on the feature later by switching to the “disable_x” branch: git checkout disable_x.
2. Writing proper commit messages
A commit message communicates what the commit does. It is for human communication, a thing that I am not good at. However, you still need to write this and your commit messages will live in the commit history forever.
There are several guidelines available on how to write proper commit messages. It is important to note that a commit message is not communicating what you have done. Instead, it is a message communicating what the commit does. A rookie mistake that I committed a lot in the past is to write something like: “Deprecated function disable_x”. This message says what you have done. Actually, no one wants to know that.
Quoting Chris Beams, a proper commit message should complete this sentence: “If applied, this commit will …”. Therefore, the subject line of a commit message should be in the imperative mood. You can also write more information than just the subject line. But it is quite difficult to write the git commit message body using the -m flag. And that brings us to the point 3.
3. No shame not using command line
It is important to master the command line Git. But it can be tedious sometimes. Increasingly often, I use magit. It is so much easier to use.
Git’s official website provides several alternative options. Even RStudio has a Git interface. I did a so-so-la-la tutorial for the Mannheim Open Science Meetup on how to use that.
4. Vaccinate
git add . is a command which one should avoid. But people (especially rookies) like to use it because it adds all files under the current directory to the index. It is an effective command.
A common side effect of this command is to add hidden files also in the index and commit into the commit history. My soul dies a little every time I see .DS_Store in a Git repo 3. As of writing, there are over 600,000 commits on Github that delete .DS_Store. Other places also see the infestation of .DS_Store. Interestingly, not even all R packages are citable, some .DS_store files are citable with a DOI.
It looks like a small nuisance. But a .DS_Store file actually contains metadata of one’s directory structure. And it can pose security concerns.
There are several solutions to this. The obvious one is not to use sweeping command such as git add .. An important message here is that it is never a good idea to commit any hidden file in general. Except some. For example, you can create a hidden file .gitignore and put .DS_Store there. If you don’t know how to do this, vaccinate. Of course, you should be vaccinated against COVID-19, but also run this R command: usethis::git_vaccinate(). Help us, help yourself.
5. Handling Pull Request
This one is an advanced topic because a rookie probably doesn’t need to handle pull requests. Also, this one is extremely opinionated.
On Github, there are a few options to handle a pull request. “Merge all of the commits into the base branch”, “Squash the commits into one commit”, and “Rebase the commits individually onto the base branch”.
I am in the team “squash”. Reasons: I don’t like to look at merge commits in the commit history. Unless you are a really reasoned developer, your PR usually contains a lot of missteps in-between. I also don’t want to look at those missteps forever in the commit history neither.
Conclusion
In this blog post, I show you how I use Git and Github. Once again, you don’t need to and should not follow all of them.
-
here, I create a term called m-branch. Some people consider the name “master branch” offensive and suggest to use “main branch” instead. I have no position on this. So, I use the term “m-branch” to represent the default branch. ↩
-
I’ve made this an alias: gdag ↩
-
Yeah, data scientists are people doing data analysis with a Mac. ↩