chainsawriot
Home | About | ArchivereadODS 1.8 is released and a hard lesson learned
readODS 1.8 is released actually in January on CRAN 1. It is the first release under the rOpenSci moniker. Last time I wrote about the release of readODS 1.7 was in July, 2020. And man, that’s long time ago. That’s like “a pandemic and a war” ago.
In that blog post, I said that “readODS 1.7 is going to be the last release in the 1.0 series.” The release of 1.8, therefore, was unexpected. But I have to. The unexpected release of 1.8 is due to the fact there are important contributions from the community and the improvement is not breaking. Therefore, there is no need to lump this into the next breaking 2.0 release. A better decision is to release it now in the 1.x series. 2
The thing is, I don’t think we should focus on any new feature if the core features of readODS are in the unusable state, as I said previously. I should focus on the core features of readODS, that are, reading and writing ODS files. And probably, I will not add any new feature to the package at least before the so-called “Projekt 71” is complete.
vfwrite_ods
The whole story should go back to January when a person bashed the super poor writing performance of readODS on Mastodon. I happened to read that message and replied with my “Projekt 71” blog post. And then that user wrote a reply about the situation of readODS and tagged some celebrities such as Hadley Wickham and asked for their help on readODS. I didn’t get any help from Hadley Wickham. But I got two persons who helped a bit on the development: Michal Lauer helped with the documentation and refactoring of some code. And then, there came the legendary Dr Detlef Steuer (he maintains the openSUSE port of R).
Dr Steuer contacted me by e-mail and said he found a way to write ODS with 100x the performance gain. He called it vfwrite_ods (very fast write ods).
Before explaining why his approach can produce 100x performance, I need to say a bit about write_ods. readODS did not have the function to write ODS when I inherited it from Gerrit-Jan Schutten. readODS was purely, as the name implies, for reading ODS. The original code for writing ODS was written by the great political scientist Thomas Leeper (now a data scientist at Meta). His original implementation was improved by several other contributors and yours truly. But the overall mechanism was to use xml2 (the R package for handling XML) to populate the data into an XML tree.
This method can certainly get the job done. But modifying a C++ pointer to a data structure (the XML tree) from R via xml2 is not exactly fast. Dr Steuer has another way to think about this operation. Instead of modifying the XML tree, make it an XML template filling exercise. To summarize it in one function, it’s like this:
.cell_out <- function(type, value, con) {
cat("<table:table-cell office:value-type=\"", type,
"\" office:value=\"", value,
"\" table:style-name=\"ce1\"><text:p>", value,
"</text:p></table:table-cell>",
sep = "",
file = con)
}
Another good idea from Dr Steuer is to use cat and the manipulation of file connection to skip many paste operations. And indeed, Dr Steuer’s implementation of vfwrite_ods can generate 100x (sometimes even more) speed improvement. After some refactoring and debugging, I added Dr Steuer’s improvement into the code base. The original implementation was not able to modify existing files (e.g. adding a new sheet). But I made it work too with the new way suggested by Dr Steuer.
Until…
Roll out your own … and fuzz
Michal Lauer wanted to close the very first issue of the package, which is about reading and writing non-ASCII characters. And actually, this issue has been plugged for a long time. I think it is prudent just to add some more unit tests.
And then I found out the new implementation didn’t work with all the input. Specifically, it didn’t work with the double quotation mark. And digging deeper into it, the problem is that XML has five predefined entities. These five entities are (amp, lt, gt, apos, quot) and they are required to be escaped. And our friend, double quotation mark, is the quot. And the solution, after a few days of digging out what’s wrong, is to escape the text.
Isn’t XML a nice format? Of course, it is partly my fault. The new improvement was not well-tested. If readODS were still using xml2, as it is based on the C++ libxml2, which numerous hours have been spent on fuzzing it. For those who don’t know what fuzzing is: Fuzzing is to generate random input either randomly or strategically to stress test a software with an intention to break the software. You will never know what kind of sh… things your users would throw at your software. So, a good software should have been underwent this kind of fuzzing to ensure the software still works under any kind of crazy situations. For example, Google has a 100,000 CPU core fleet to continuously fuzz numerous open source projects.
Before I merged anything to readODS, I should fuzz it. But I didn’t. Also, the test cases for write ODS were very tame. As now, we have rolled out our own sh… thing, we need to fuzz it ourselves. This is the hard lesson learned.
Some tips on how to fuzz your software: stringi has a really nice function for it:
stringi::stri_rand_strings(10, 10, "[\u0001-\uCFFF]")
You can also customize the UTF-8 range. For example, the following generates mostly symbols and arrows:
stringi::stri_rand_strings(10, 10, "[\u2190-\u228F]")
For readODS 1.8.0, I added fuzzing-based unit tests to ensure your whether input is supported. And it is now safe to write whatever content as ODS to your heart’s content. Pronouncing this sentence is a good English exercise.
Speed gain
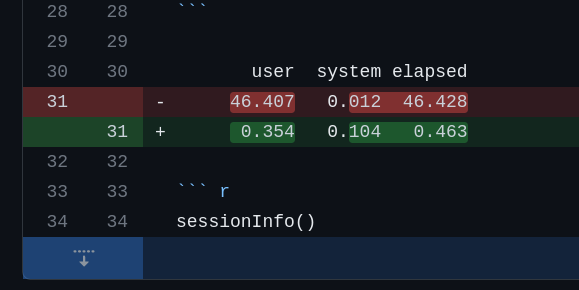
And now, speed benchmark is also a routine check. Compared with Dr Steuer’s original implementation, the safety improvement (escaping) slightly impacts the performance. But still, writing a 3000 x 8 data frame now takes 0.561 second. It is a dramatic improvement from 46.428 seconds using readODS 1.7.3.
Acknowledgment
I would like to thank Detlef Steuer and Michal Lauer for their help to make readODS 1.8.0 possible.
-
Like many of blog posts, this had been stuck in my heap of drafts since January. ↩
-
It is important to remind our developer friends that if you use semantic versioning scheme like v1.7.3, please respect that. Don’t release breaking changes in minor versions or even the patch versions! And changing the output data format (e.g. adding columns) with the same parameters is a breaking change. ↩