chainsawriot
Home | About | ArchiveTop 5 most important textual analysis methods papers of the year 2020
I promised to write this on Twitter in Janurary. Alex Wuttke and Valerie Hase said they are interested in reading this. However, the unfinished draft had been in my draft directory for almost a year. I don’t know if they are still interested in reading it anymore. The year 2021 is almost apass. Like always, I was too ambitious. I think I should be practical and write a scale-down version of this. Don’t expect it to be the same as the one last year (e.g. no detailed elaboration of the honorable mentions). As time has been stretched longer, I can really see how these papers influence my own research in 2021. I have cited the following papers many times. So the delay can be a good thing.
The rules are the same though. 1
- The method should deal with “inconvenience middle” datasets
- The method should deal with multilingual datasets
- The method should be validated and open-sourced
Before I move on, I think I need to emphasize that in 2020 and early 2021 some communication journals, broadly defined, published methodological special issues. For example, Journalism Studies, Political Communication, and the German language M&K Medien & Kommunikationswissenschaft.
Some papers in the following list might officially be published in 2021. But they are online-first in 2020. Again, I am super biased and the list represents my clumsy opinion, which is not important and not significant. If I omited any paper, please forgive me. I am a sinner.
Without further ado, here is the list of the top 5 most important — I think — papers.
- Watanabe, K. (2021). Latent semantic scaling: A semisupervised text analysis technique for new domains and languages. Communication Methods and Measures, 15(2), 81-102. doi
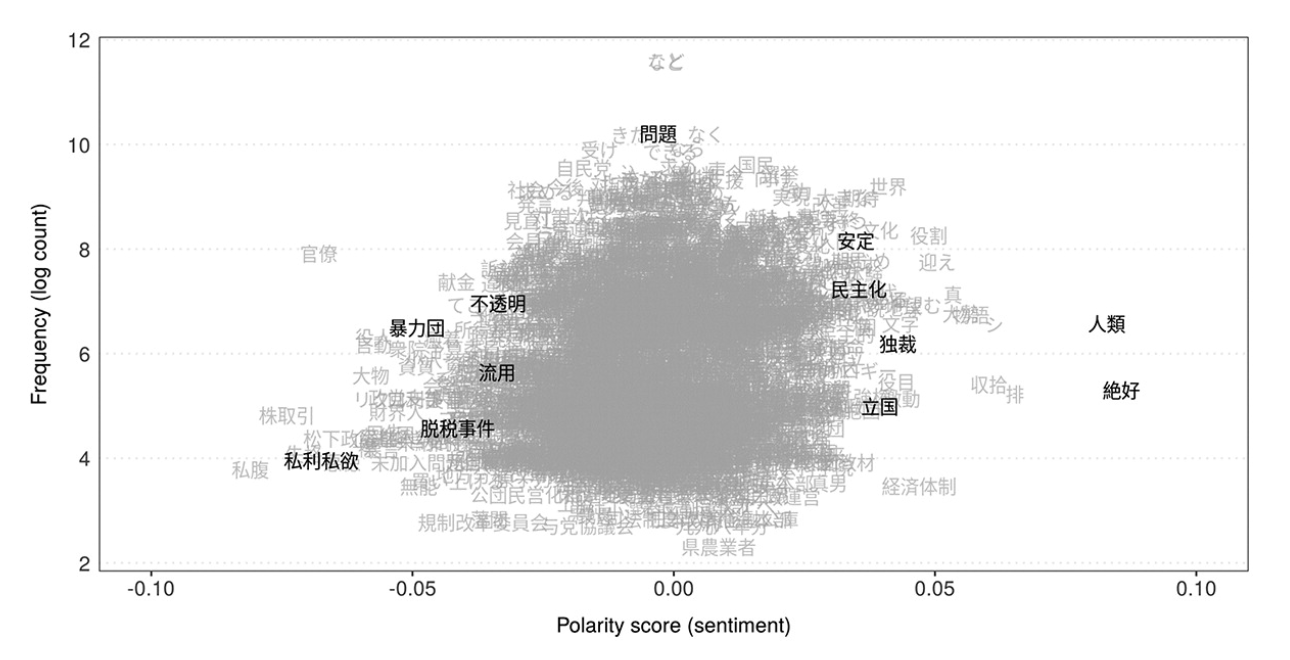
I think this is probably the first paper which really introduces semisupervised methods to the scene. Yes, the same author has two previous papers on semisupervised methods: 1. the newsmap paper and 2. another paper dealing with creating seed dictionaries for seeded LDA. This paper introduces a new method that communication scientists can readily use. The most important reason why I like this paper a lot is of course the R package LSX.
The design of the method is really clever: with a seed dictionary, the method uses SVD (or other word embedding techniques) to identify words in the corpus that are similar to the seed words and assign weights accordingly. The paper demonstrates the method’s applicability for English and Japanese data. My experience suggests the method also works for German data. The R implementation LSX is incredibly fast, thanks to the proxyC engine by the same author.
Semisupervised methods are a nice idea. But my experience told me one should still validate the results.
Honorable mention: Baden et al. (2020) Hybrid Content Analysis: Toward a Strategy for the Theory-driven, Computer-assisted Classification of Large Text Corpora. Communication Methods & Measures. doi
This one is also trying to tackle the problem of unsupervised methods, but in a different way.
- Kroon, A. C., Trilling, D., & Raats, T. (2021). Guilty by Association: Using Word Embeddings to Measure Ethnic Stereotypes in News Coverage. Journalism & Mass Communication Quarterly, 98(2), 451-477. doi
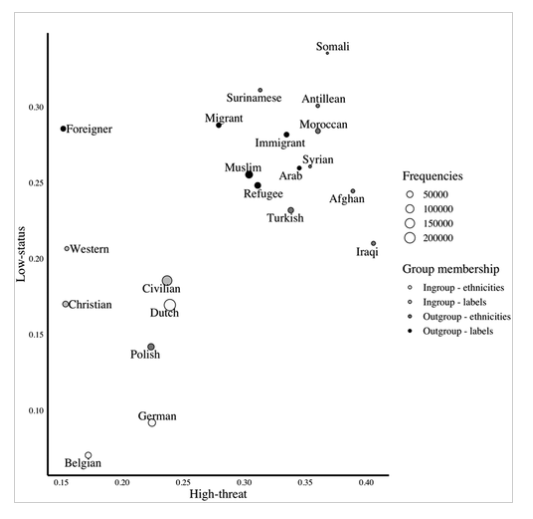
This one might be the first major article published in a communication journal that uses locally trained word embeddings to study implicit sentiments in new coverage (correct me if I am wrong). Of course, there are quite a number of papers published in those big journals, e.g. Caliskan et al. (2017), and Garg et al., (2018). These papers use pretrained word embeddings trained on large corpora of text.
Being the first in communication journal, the Amsterdam team creates locally trained word embeddings on Dutch news coverage and then measures the cosine similarity between words representing minority groups (e.g. Surinamese) and negative attributes (e.g. words representing low-status and high-threat stereotypes).
Of course, there are many ways one can critique the study 2. But the paper opens the door for applying the “1st generation” context-blind word embeddings in the analysis of news articles. The bug (word embedding biases) is actually a feature here.
- Song, H., Tolochko, P., Eberl, J. M., Eisele, O., Greussing, E., Heidenreich, T., Lind, F., Galyga, S., & Boomgaarden, H. G. (2020). In validations we trust? The impact of imperfect human annotations as a gold standard on the quality of validation of automated content analysis. Political Communication, 37(4), 550-572. doi
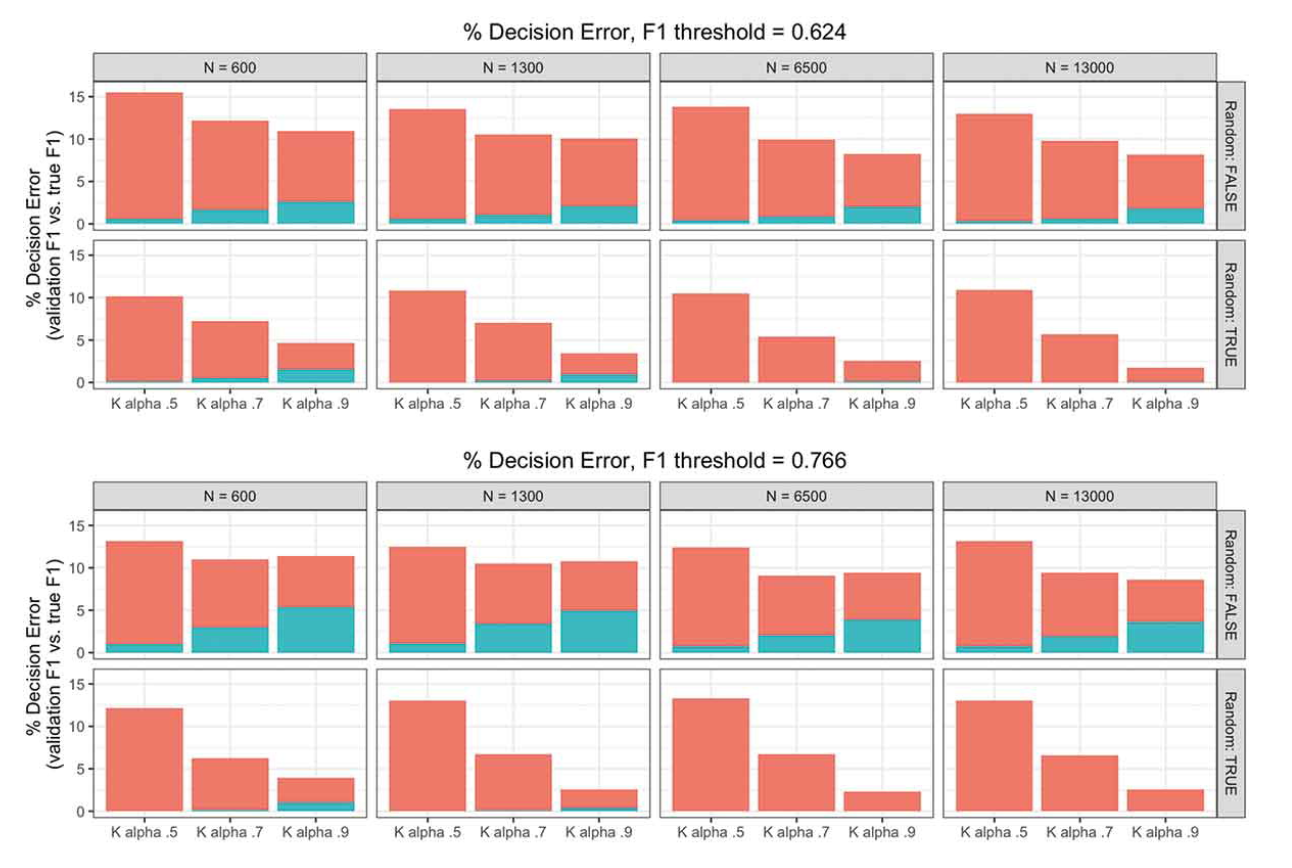
Krippendorff outlines the relationship between intercoder reliability and validity in content analysis in his “bible”. He basically says that when there is no intercoder reliablity there is also no validity. The study by the Vienna team demonstrates this point for automated content analysis using Monte Carlo Simulations. The paper points out the overemphasis of the automated part of automated content analysis while a good automation depends on the quality of the manually coded data. The discussion section of the paper contains some recommendations for improving validation practices. 3
- Nicholls, T., & Culpepper, P. D. (2021). Computational identification of media frames: Strengths, weaknesses, and opportunities. Political Communication, 38(1-2), 159-181. doi
Similar to the previous one, this is in the category of “when computational methods don’t work” and I have an affinity to these papers.
The greatest abuse of topic models is to treat topics as frames 4 and this paper shows exactly this point. Once again, topics are not Entmanian frames.
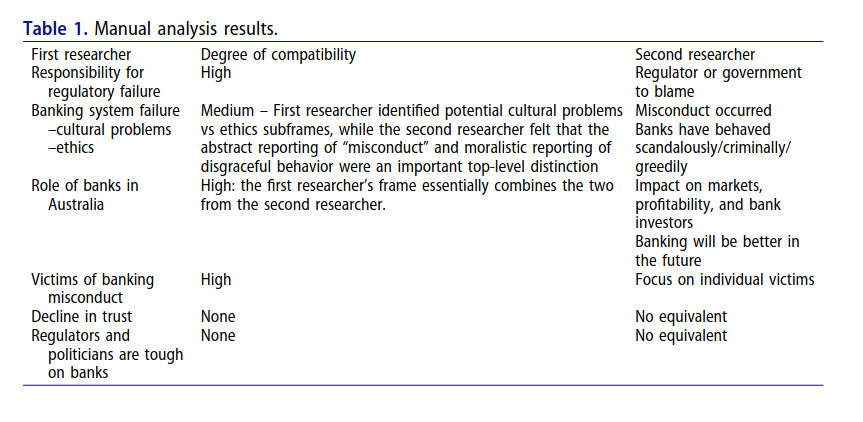
But I think this paper also reveals something about manual annotation of frames (Table 1 in the original paper). Actually, human coding of frames could vary between individuals. Computers, on the other hand, can generate “frames” with perfect reliability but with very low validity. There are still a lot of rooms to improve this, I think.
Honorable mention: Hopp et al. (2020) Dynamic Transactions Between News Frames and Sociopolitical Events: An Integrative, Hidden Markov Model Approach. Journal of Communication doi
Moral Foundations Dictionary, umm….
- Barberá, P., Boydstun, A. E., Linn, S., McMahon, R., & Nagler, J. (2021). Automated text classification of news articles: A practical guide. Political Analysis, 29(1), 19-42. doi
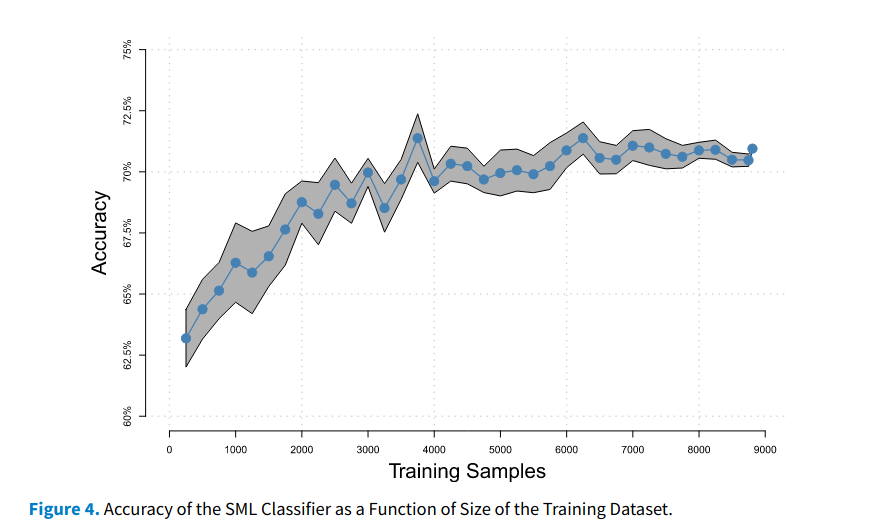
This is also in the category of “when computational methods don’t work”. This time the dictionary methods. As a guide, this paper is quite good. It explains every decision in the process of doing automated text classification. Empirically, this one shows that news tones do not require very sophisticated supervised methods, e.g. deep learning, to detect. A simple regularized logistic regression can easily outperform dictionary methods. If there is a need to validate an off-the-shelf dictionary with manually annotated data, why doesn’t one just use the annotated data to train a simple supervised machine learning model?
Following the previous paragraph, I’ve recently started to wonder: I think most properly trained supervised machine learning models would have an accuracy of ~75% to predict constructs that we (communication researchers) are interested in. They are certainly useful, no doubt about it. But HOW helpful are they? I like to think about it using human analogy as a Gedankenexperiment. Suppose I know my student helpers will incorrectly code the provided data 25% of the time, would I still hire them? Would I be worried about the quality of my research based on the annotated data by these student helpers?
When I replace the word “student helpers” with “machine learning models”, would you come to the same answers to all these questions?
-
Actually, there is a hidden rule: I can’t pick my own shit. For example, the oolong or rectr paper… Well, compared with these papers, my papers are really… my own shit. ↩
-
For example, using the STAB notation (ST being targets, AB being attributes), the study only uses S and A, i.e. one target group and one attribute group. I think it is accepted that adding B would probably make the results better. Moreover, like all of the word embedding bias detection methods, the measurement is at the corpus-level, not at the sentence- or article-level. I still don’t know how to properly validate these methods. Previously, these methods were validated by either showing the “intelligence” of the trained word embeddings (e.g. analogy test) or showing the correlation between the word embedding biases and real-life indicators of social biases. These are not true validation. ↩
-
And those recommendations influence several design decisions of oolong. And I promise not to talk about my own shit, so it is in a footnote. ↩
-
I must admit, I abused it once too. I am a sinner. Repent ye, for the kingdom of heaven is at hand. Please forgive me. ↩