chainsawriot
Home | About | Archive2021 Wrapped: R edition
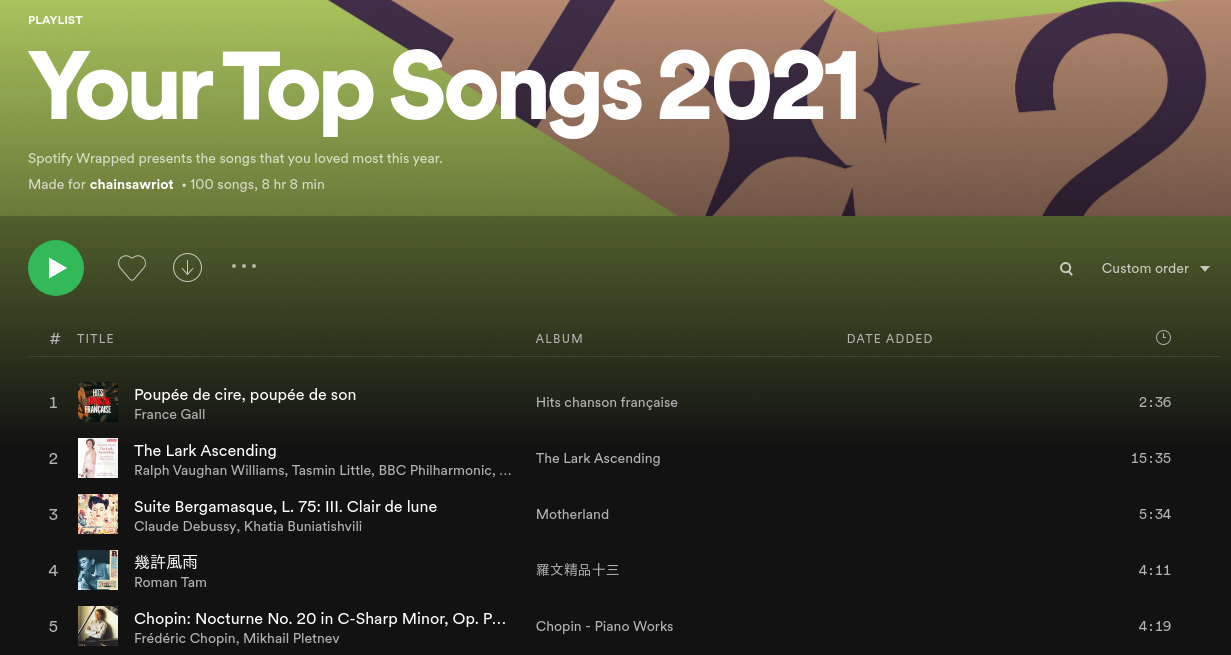
Spotify releases to the users every year “a Wrapped” on Dec 1st: it is a descriptive summary of listening habit. My Spotify Wrappeds are quite embarassing because they reveal that I listen to music more when I am down.
And then I came across this tweet by Emily Riederer.
Well, it sounds fun. I think it would be possible to generate a Wrapped for my R code because I have all my projects in my ~/dev directory. My first idea was to just check the require and library lines 1. And then I know that it is a stupid idea because Javascript also uses require. So I should focus on R files (*.R and *.Rmd).
My initial try was pure R. The idea is to use the fs package to list out all R files with a modification date after 2021-01-01, select all require and library lines, and then count. Then I knew that it is super slow using the readLines function to read all R files and then extract the lines I need. Even with multicore computation of furrr, it is still slow.
My second try was to not to use R entirely. Instead, I used the wonderful ripgrep to search for require and library lines. I usually use ripgrep from within emacs via the rg mode. So I needed to learn how to use it from the command line.
rg '^library\(|^require\(' -g '*.{R,rmd,r,Rmd}'
So, it searched for all the require and library lines in all of my R files. Then I redirected the result to a text file.
rg '^library\(|^require\(' -g '*.{R,rmd,r,Rmd}' > rgresults.txt
The file is incredibly small and is machine readable. I then analyzed the data from there. Here are my most used R packages in 2021.
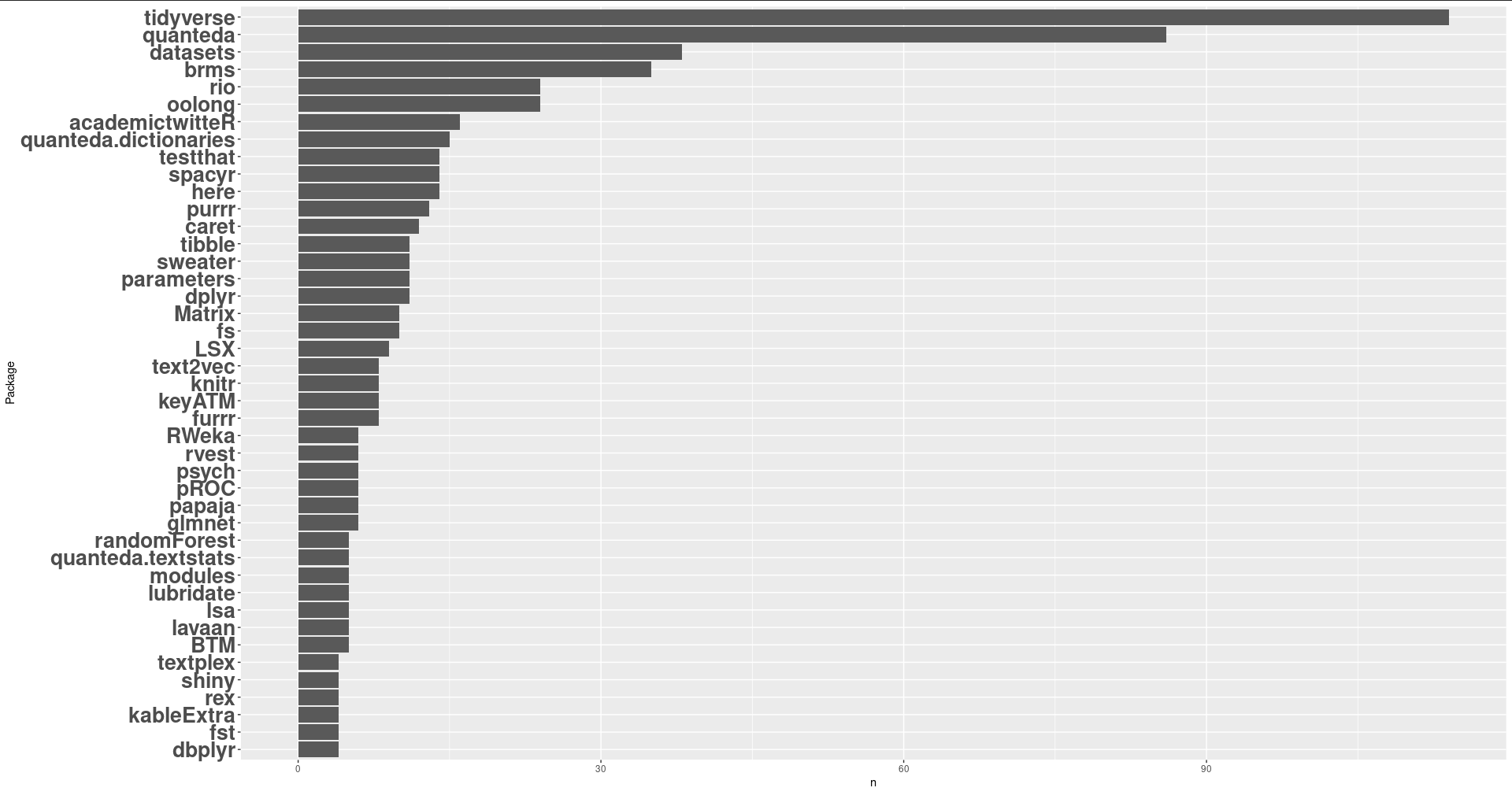
I notice one problem here: the large usage of the datasets package. As it turns out, those uses are from the test cases of rio and readODS. So, after filtering out all test cases. I think the following figure is more accurate.

I think it reflects my laziness to load tidyverse instead of individual packages from tidyverse. Actually, it reflects who I am: doing a lot of text analyses with quanteda (and its friends such as quanteda.dictionaries, spacyr, LSX, quanteda.textstats etc.) and Bayesian modeling with brms. You might think that I do twitter analysis with academictwitteR. But the fact is that I don’t do (actually …. like…) twitter research. I just happen to contribute some code. Also, I need to use the package to answer the questions in the dicussion forum.
I do dogfooding too: I use my own packages - oolong, sweater, textplex. rio is kind of that too. The very reason to package these oft-repeat code into packages is for using it in research, right?
It also reveals some packages I really like: here, papaja, text2vec, parameters, etc. These are massive time savers.
-
From my rstyle project, I know that the most accurate way to do that is to parse the code using base::parse into expressions and then actually count from there. Also, code that use the namespace operator, e.g. rio::import, is not counted as a use. But I am too lazy and I don’t need the most accurate result. ↩