chainsawriot
Home | About | ArchiveAdaptive researcher series #1: how to overengineer your bibliography management (for good)
tl;dr You don’t need to do this.
About this series
You might have the software knowledge to make your research better. However, you are working in a collabration environment that makes the knowledge very difficult to apply. This “adaptive researcher” series is about how to be adaptive so that you can still apply your knowledge in your research. It is basically me sleeptalking.
Bibliography management
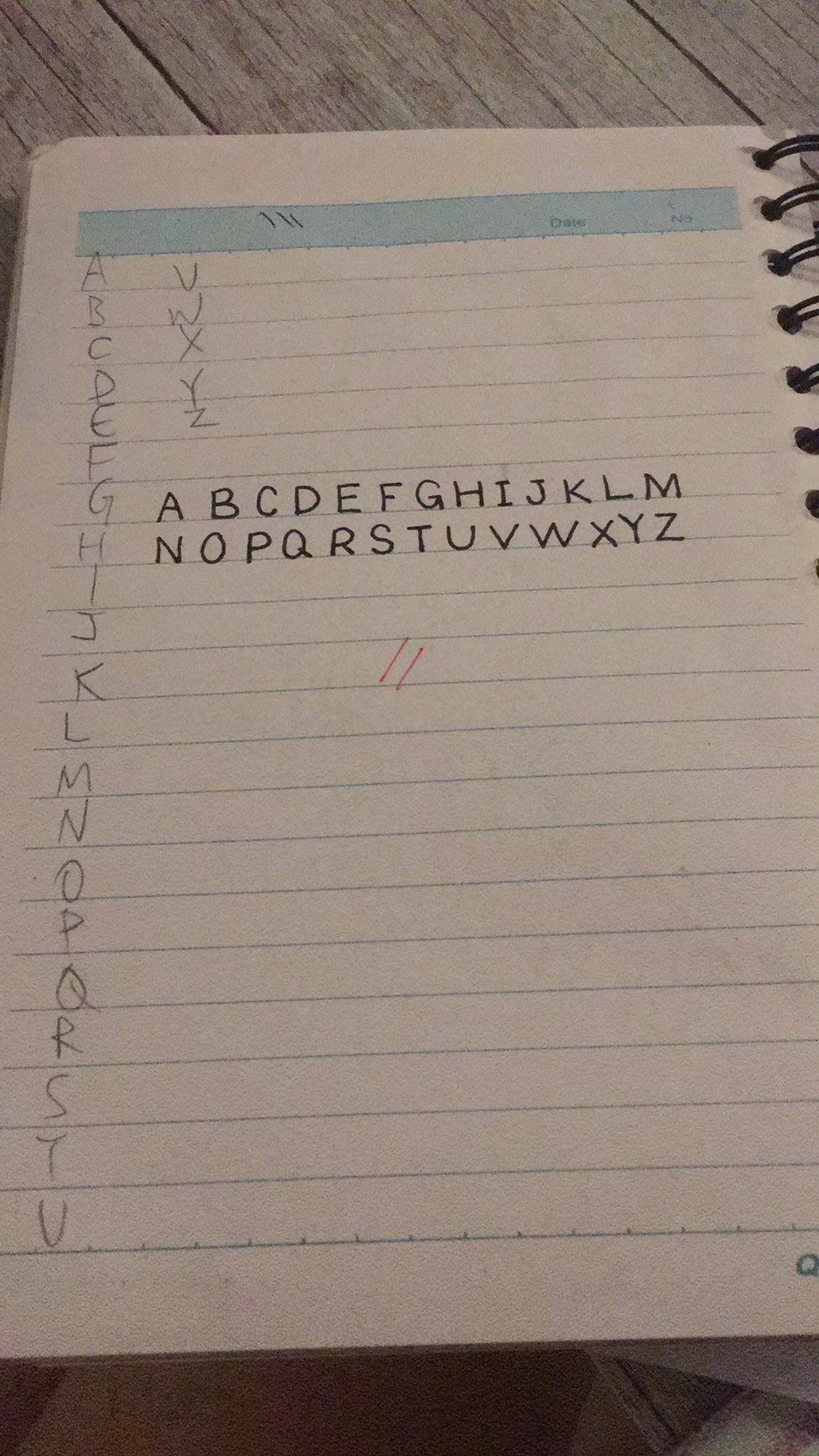
I have a confession to make: In almost 90% of the manuscripts, I managed the bibliography manually. So, I have a page in my notebook like the above. Even after I have earned a PhD, I cannot remember the order of English alphabets.
I don’t usually use bibliography management software.
Skippable prologue: my personal history
I have never installed EndNote. The very fact that it is a commercial software makes me angry. Believe it or not, I have tried almost all of the free bibliography management solutions. Back in the hospital, I have tried RefWorks. RefWorks is actually a web-based bibliography management… it is too long to type. Let’s call it BMS. I have convinced my boss back then (a doctor, the one who literally saves lives) not to mess with the markups in the word document. My RIS-based reference database is stored online. It was the time before the term Cloud is invented.
After the tiring editing and reediting of the article, I need to connect to the HKU library using my boss’s VPN account; connect to RefWorks; Upload the word document; Convert the markups; Generate the reference list; Download the word document. It was actually quite okay. But still, it is commercial. So, I used it for a few manuscripts. Not a long term relationships. After I quited medical research, I don’t even want to use it anymore.
Then I have tried quite a number of BibTex-based free software, e.g. BibBase, BibDesk, JabRef and some other solutions I’ve forgotten. The problem was, I mostly worked with Microsoft Word back then. These solutions were not so useful.
The one that almost became my regular is Zotero. It is nice actually: good integration with almost all writing software (Microsoft Word, Libreoffice Writer, text-based formats such as LaTeX / Markdown and even an experimental support for Google Docs) and it is cross platform. I used it partially in my PhD thesis. But the final version, I still resorted to manual editing. After the graduation, I have tried very hard to use Zotero more often. But it doesn’t stick. Of course, it has something to do with online collaboration. I think 90% of my writing is done through Google Docs these days. The Google Docs support is experimental but actually quite okay. However, I don’t know how to share my Zotero with my collaborator. Or, I don’t even care to google how to do that.
Another significant portion of my writing is now in plain text formats. To be honest, I enjoy writing in emacs and then collaborate with tech-minded people on Github than writing collaboratively on Google Docs. But you can’t force your boss and your collaborators to use plain text formats. Believe me, it is even harder than in the 00s when you wanted to convince your boss or friends to use OpenOffice.Org.
For plain text writing, BMS is boiled down to only BibTex. With this introduction, I think it’s time to jump to the nonskippable part of this article.
BibTex

BibTex is a plain text format. All major databases can export BibTex. My go-to database, Google Scholar, of course can export a record as BibTex. What I did previously, is to copy the BibTex content and then paste it into a text file.
I don’t have a database of BibTex files. I usually do it in an ad-hoc manner: I need to write a paper, so I collect all papers I need to cite in a .bib file for that paper.
As said, more and more of my papers are now written in plain text and I think I can’t do it in an ad-hoc mode anymore. Also, more and more reviewer comments are criticizing the accuracy of in-text citations. I think the problem here is that I don’t have a lot of time manually adjusting in-text citations in my manuscripts. Accuracy hurts.
Gary King has a Github repo of his BibTex file. If he does it, I should do it too.
And of course, with my signature: overengineering.
The source of BibTex
The original design of BibTex is for you to type in the information yourself. But I think in this era, no one would need to create BibTex oneself. I need to do that sometimes, especially for tedious things such as records of ICA presentations. But I think one probably should not repeat this effort for “easy” things such as papers.
As said above, my go-to server is Google Scholar and it can actually generate the BibTex file of your search result.
However, I must emphasize: It is my go-to server for searching papers, but it is usually not my go-to server for generating Bibtex files. The reason? Digital Object Indentifier or DOI. Google doesn’t have DOI information. And almost all modern journals are expecting you to list DOIs of your cited papers. 1
So, if you use the BibTex file generated by Google, you usually need to enter the DOI yourself. That’s almost like reentering the BibTex anew and of course, that’s bullshit.
AFAIK, only one database can provide DOIs and that server is Crossref. Well, because Crossref is the official DOI registration agency. They devour the monies from publishers (and well, publishers devour our monies either through subscription fee or APC. They devour our intellectual labour too.) so Crossref needs to make the complete registry public.
As a search engine, Crossref’s search quality is abhorrent. So, don’t use it for literature review. But if you have a specific paper in mind and you want to get its DOI, it’s perfect, however.
What’s better? It has a RESTful API. Well, it has rate limits. But that’s not Twitter or Facebook API. You shouldn’t use it very often, right? right?
And that moves us to the next section.
biblio
A RESTful API should talk to your software, not you. For example, you can use rcrossref to query Crossref with R. But that’s not I am going to do because my goal is to have a BibTex database. And a BibTex database is plain text. And there is only one software one should use to manipulate plain text.
Notepad++ v7.8.9: Stand with Hong Kong Edition.
Sorry, I am kidding. Emacs. Emacs. What else do you expect from this blog?

With biblio, I can query crossref with M-x crossref-lookup . Then I can enter the query string in the minibuffer. If the paper is found, I can just press I. And I got the BibTex (with DOI) in my current buffer.
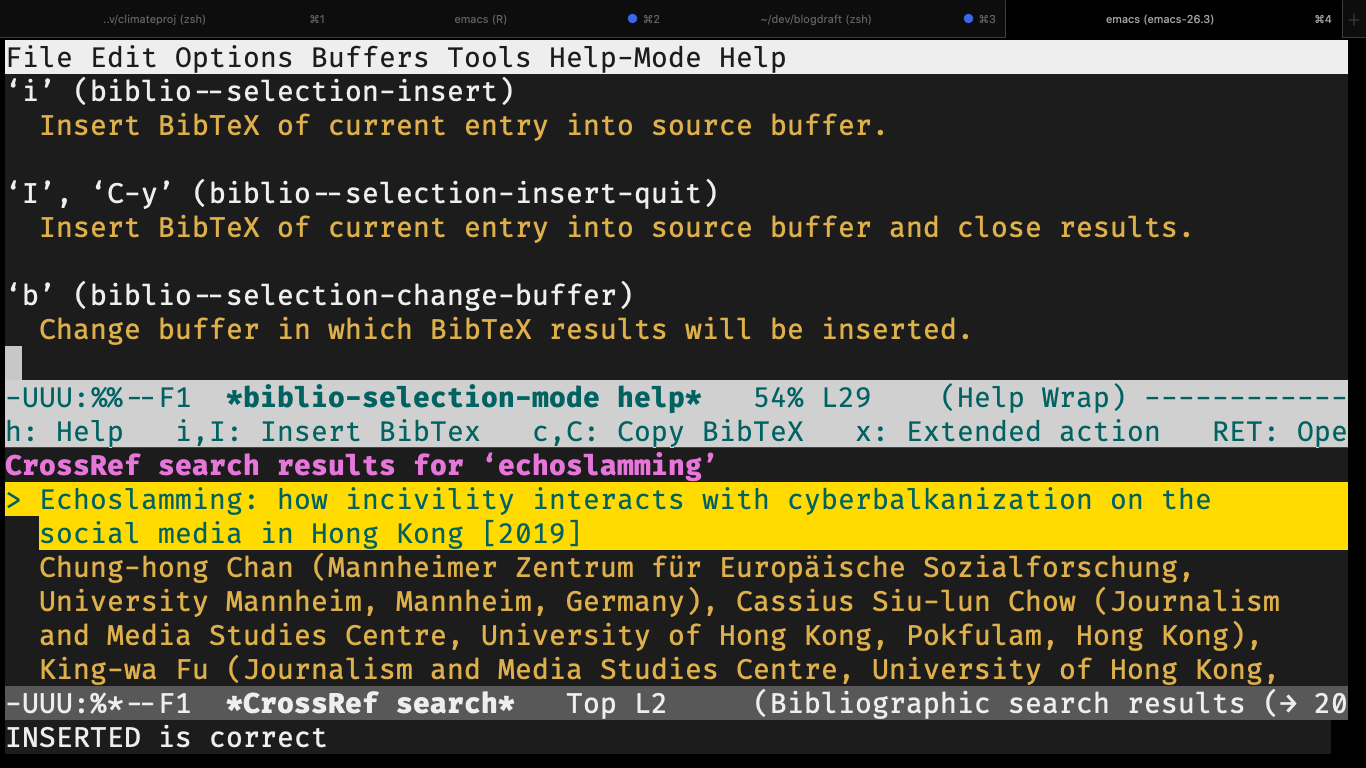
Leistungsfähig!
Maybe I need to edit the cite key a bit. But it has been super good already. But can I make it über good?
Literate programming
Inspired by this blog post, it is possible to annotate a BibTex with literate programming.
So, what the heck is literate programming?
The idea by Donald Knuth is to mix both documentation and program together. The documentation is written in human language (e.g. English) to explain the program. One can then use a procedure called “tangle” to extract all source code; a procedure called “weave” to extract all documentation.
Does it sound familiar? If you are coming from R, you might have used Sweave. Or more popular, R Markdown. Now you know why it is called “Knitting a R Markdown” (referencing Knuth’s “weave”). Or maybe you have used IPython notebook, or Jupyter notebook. The same idea.
Well, the old uncle of these solutions is Org mode. Before the widespread adoption of R Markdown and Jupyter, Org mode was proposed as the solution to reproducible research2. But well, it seems that it is just a solution to reproducible research now. Maybe not a very popular one.
Imagine a solution that ties in with Emacs. You then know why it is not very popular. Just use the most popular solution. I use R Markdown too. I used Jupyter. But not so much anymore.
How can literate programming help me with this? Here’s how.
Annotated everything
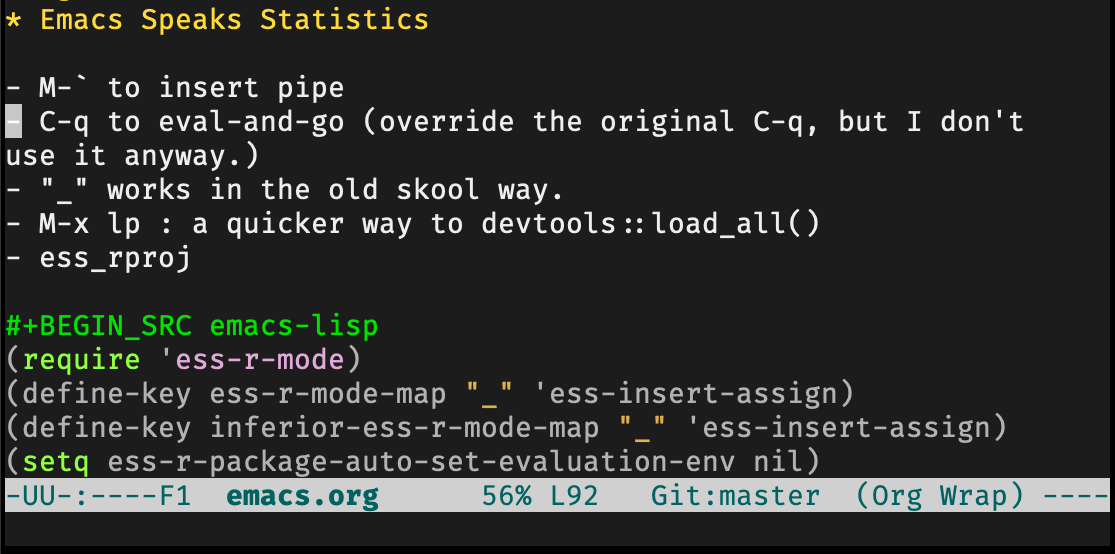
R Markdown tried very hard to be language agnostic. So that you can write Python or Bash or C++ in your R Markdown document. Jupyter tried even harder, it supports multiple kernels.
Org mode is truly language agnostic. You can mix almost all programming languages on the planet.
But what the heck is org mode?
Org mode is originally an outliner. So you can write an outline like this.
* 7 Habbits
** Independence
*** Be proactive
I want to be reactive.
*** Begin with the end in mind
I want to put end in mind.
*** First things first
But usually, first things come last.
** Interdependence
*** Think win-win
But the world encourages zero sum.
*** Seek first to understand, then to be understood
What if no one can understand you?
*** Synergize
What if we have corona?
** Continual improvement
*** Sharpen the saw; Growth
I use a chainsaw.
If you have some code, you just mingle that into your outline and insert a code block like this:
* ess_project
Loading ess_project as described in this [[http://chainsawriot.com/mannheim/2020/07/19/elisp.html][blogpost]].
#+BEGIN_SRC emacs-lisp
(load-file "~/dev/ess_rproj/ess_rproj.el")
(add-hook 'ess-mode-hook #'ess_rproj)
#+END_SRC
There are some configurations you can do with the code block. The obvious one is the language in this block. In this case, it is elisp. In emacs, you can just type <s and then press Tab. It will then expand into a template of code block.
The best use case for Org is to annotate your configuration files. Not only your typical .emacs file, but literally any configuration files in plain text. Suppose you have a typical .zsh configuration file. You can use Org mode to create an annotated version.
These are my R-related alias
#+BEGIN_SRC shell
alias rr='Rscript -e'
alias rdoc='rr "devtools::document()"'
alias rcheck='rr "devtools::check()"'
alias rmegacheck='rr "devtools::check(manual = TRUE, remote = TRUE)"'
alias rtest='rr "devtools::test()"'
#+END_SRC
Actually, you can add a result block with #+RESULTS: to execute the code block and display the results there. But it is not I want to do today.
As you can imagine, it can also support Bibtex. So you can do something crazy like this.
* Chan_2019
This is the worse paper from my PhD thesis. You should read citep:Papacharissi_2004 instead.
#+BEGIN_SRC bibtex
@Article{Chan_2019,
author = {Chan, Chung-hong and Chow, Cassius Siu-lun and Fu,
King-wa},
title = {Echoslamming: how incivility interacts with
cyberbalkanization on the social media in Hong Kong},
year = 2019,
volume = 29,
number = 4,
month = {May},
pages = {307–327},
issn = {1742-0911},
doi = {10.1080/01292986.2019.1624792},
url = {http://dx.doi.org/10.1080/01292986.2019.1624792},
journal = {Asian Journal of Communication},
publisher = {Informa UK Limited}
}
#+END_SRC
I can give a little summary of the paper (maybe a three-sentence summary, like I did with books) and even display the relationship between papers.
This annotated version is for our mere souls like me to read. Github has native support for org and renders them nicely on the web. But what if you need a version that you can use in your writing: The actual BibTex file.
It takes one to tangle.
Exporting BibTex
If I add a PROPERTY header to this org file, e.g.
#+TITLE: My Bib
#+PROPERTY: header-args :tangle chc_articles.bib
* Chan_2019
This is the worst paper from my PhD thesis. You should read citep:Papacharissi_2004 instead.
#+BEGIN_SRC bibtex
@Article{Chan_2019,
author = {Chan, Chung-hong and Chow, Cassius Siu-lun and Fu,
King-wa},
title = {Echoslamming: how incivility interacts with
cyberbalkanization on the social media in Hong Kong},
year = 2019,
volume = 29,
number = 4,
month = {May},
pages = {307–327},
issn = {1742-0911},
doi = {10.1080/01292986.2019.1624792},
url = {http://dx.doi.org/10.1080/01292986.2019.1624792},
journal = {Asian Journal of Communication},
publisher = {Informa UK Limited}
}
#+END_SRC
I can tangle it as a BibTex file (chc_articles.bib) that I can use. The keyboard combination is M-x org-babel-tangle.
If I don’t prefer to open emacs, I can tangle the org file with this shell function:
function tangle() {
emacs --batch -l org --eval "(org-babel-tangle-file \"$1\")"
}
FAQ
Instead of ending this blog post with a usual conclusion, I would like to interview myself.
Q: Why? Seriously, Why?
A: There is no point doing this. It is more in the realm of “because I can”. You may use software x for effectively the same thing, as the software I have listed: Zotero, BibCite, RefCite or whatnot. But the obvious advantage of this method is all in plain text. So that you can version control the whole thing.
Q: Is it perfect?
A: Obviously no. There are still much room for improvement. For example, I might develop a way to select all cite keys in a markdown document; query my annotated BibTex org file; and then tangle it into a BibTex file.
Q: Why don’t you just use Org-ref?
A: Good question. I don’t know.
-
Of course, there are … interesting journals that still don’t want to pay $275 per year and $1 per new DOI, e.g. International Journal of Communication. At some points, I wanted to start a patreon account for IJOC so that the journal can offer DOIs. But I scraped this recurrent idea. There are actually alternative “cheap” way to obtain a DOI, e.g. Zenodo… oh shit, I have diverted too much. ↩
-
Schulte, E., Davison, D., Dye, T., & Dominik, C. (2012). A multi-language computing environment for literate programming and reproducible research. Journal of Statistical Software, 46(3), 1-24. ↩