chainsawriot
Home | About | ArchiveWeek 7: Creation of semantic networks
After two R&Rs and one paper rejected by ICA, I am back.
I am quite busy building stuff (that no one uses). So this week, I will expand an e-mail consultation into a blog post, a practice championed by Andrew Gelman.
An old colleague of mine asked me over e-mail about how to conduct text analysis. In particular, how to create a semantic network.
First, I would like to give a brief overview of the current stage of text mining in R.
In the ancient time, there is only one definitive package for doing this kind of stuff: tm. I have used this package for a very long time. Many of the papers that I have published during my HKU day are made possible by tm (e.g. the high-cited IEEE Internet Computing paper). But I think this package has a lot of idiosyncrasies, which I don’t think it is a good package to do text mining anymore.
Of course, over the years, there are many attempts to implement better text mining solutions to tm. One of the most famous is (tidytext)[https://www.tidytextmining.com/]. Riding on the popularity of tidyverse, this package by two R celebrities Julia Silge and David Robinson has gained a lot of traction. I have tried to make use of this package in some of my research, but I ultimately gave up. The major problem of the tidytext approach is how wasteful it is to manage words in a corpus as a data frame. It is no larger practical when the original data size is around 10% of the main memory. Not to mention the unnatural experience of making dictionary-based methods a join table operation. In summary, some ideas of tidytext maybe nice, but not practical in my research.
The package that I like, is quanteda. It is a package written by social scientists for social scientists. It is a perfect balance of practicality and ease of use. If there is only one reason why I use R for computational analysis than Python, is the availability of quanteda for R but not for Python. Unfortunately, the developers of this package are not in celebrity-status and therefore, it is like data.table, being an underground rock star.
I love the way quanteda reuse old ideas from traditional text mining practices (e.g. storing document-term matrix as a sparse matrix in memory, rather than a data frame) but with a sane, approachable user interface.
So, back to the consultation: how to construct a semantic network. Here, let’s assume semantic network means “co-occurrence network”: two words are related if they co-occur in the same document.
Quanteda makes it very easy to create such network because it provides a handy data structure called fcm (feature-occurrence matrix). This matrix is important, not only because it is the backbone of many word-embedding methods, but also it is a type of adjacency matrix which can be directly converted to a network. Because the underlying sparse-matrix implementation of quanteda’s fcm and igraph’s adjacency matrix is the same, they are interchangeable.
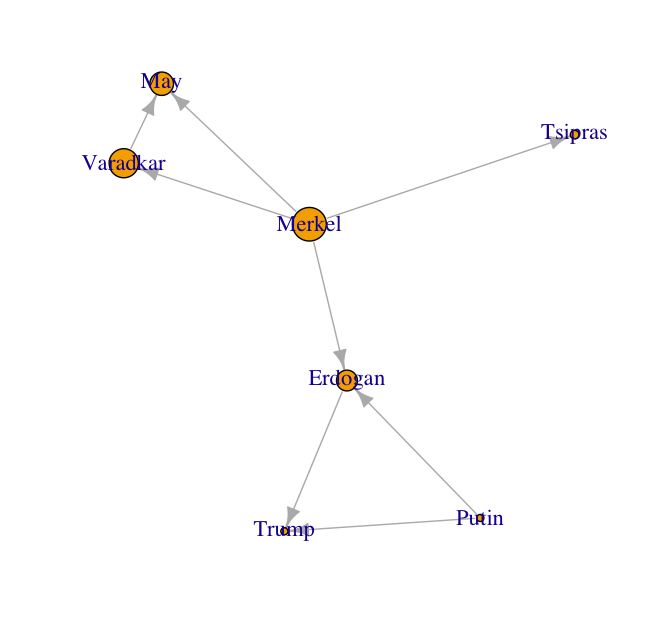
Suppose I have four articles and a list of actors (Merkel, Tsipras, May, Varadkar, Putin, Trump, and Erdogan), how to visual the relationships between all actors as inferred by the text? With quanteda and igraph, it is pretty straight-forward.
require(quanteda)
require(igraph)
text1 <- "PROTESTERS have clashed with police in Athens during a demonstration against German Chancellor Angela Merkel ’s two-day visit to Greece. Police fired tear gas at demonstrators who carried flags and banners. Dramatic video footage shows protesters shouting as they take to the streets. The riots were sparked by the German Chancellor’s arrival in Athens earlier today for talks with Greece's Prime Minister Alexis Tsipras."
text2 <- "It was straight back down to business for German chancellor Angela Merkel this week as she requested a phone call with Taoiseach Leo Varadkar to try and thrash out how the European Union might salvage its Brexit deal with the UK. The call lasted for 40 minutes. “It was an opportunity to kind of brainstorm a bit as to what we could do to assist prime minister Theresa May in securing ratification of the withdrawal agreement,” Varadkar said afterwards."
text3 <- "With the U.S. preparing its exit, Russian President Vladimir Putin and Turkish President Recep Tayyip Erdogan have assumed the lead in shaping Syria’s future. At a meeting in Moscow between the two countries’ foreign ministers and intelligence chiefs on Saturday, they agreed to coordinate next steps and professed a common interest in clearing the country of terrorist groups. “I campaigned on getting out of Syria and other places,” Trump said Monday on Twitter. “Now when I start getting out the Fake News Media, or some failed Generals who were unable to do the job before I arrived, like to complain about me & my tactics, which are working. Just doing what I said I was going to do!”"
text4 <- "German Chancellor Angela Merkel told Erdogan in a phone call Sunday that she expects Turkey to act with “restraint and responsibility” after the U.S. withdrawal, according to a government spokeswoman. Merkel praised Turkey for taking in millions of Syrian refugees, the spokeswoman said."
### SUPPOSE YOU HAVE A LITS OF ACTORS
actors <- c('Merkel', 'Tsipras', 'May', 'Varadkar', 'Putin', 'Trump', 'Erdogan')
test_fcm <- fcm(corpus(c(text1, text2, text3, text4)), context = 'window', window = 20) ### Consider only a 20-word window.
adj_matrix <- fcm_select(test_fcm, pattern = actors, valuetype = 'fixed')
plot(graph_from_adjacency_matrix(adj_matrix, weighted = TRUE, diag = FALSE))
test_fcm2 <- fcm(corpus(c(text1, text2, text3, text4)), context = 'document') ### Any co-occurrence
adj_matrix2 <- fcm_select(test_fcm2, pattern = actors, valuetype = 'fixed') ### Notice Merkel and Tsipras are connected.
co_occur_network <- graph_from_adjacency_matrix(adj_matrix2, weighted = TRUE, diag = FALSE)
eigen_centrality(co_occur_network)$vector ### Merkel has the higest eigen vector centrality
plot(co_occur_network, vertex.size = eigen_centrality(co_occur_network)$vector * 15)
If you want to know more about quanteda, the official website has a lot of tutorials. If you need a German language tutorial, Cornelius Puschmann has prepared one.
7 down, 45 to go.