chainsawriot
Home | About | ArchiveKünstler Intelligenz für Deutsch lernen
I want to talk about something technical this week. Probably this is the reason why I switched to English.
Introduction
For English- (or Chinese-)speaking foreigners, I think the biggest initial hurdle for German learning is grammatical gender. The way to tackle it, as advised, is to bruteforce remembering the article associated with the noun, such as die Zeitung, das Fenster, der Apfel. Germans claim they have the intuitive feelings to determine nouns’ gender. But they can’t describe intuitively how these “feelings” work as a set of rules. We know that some endings in German associate with grammatical gender, such as nouns end with “-keit” is almost always feminine. But these rules are fuzzy. For example, Vatter is Masculine, but Mutter and Schwester are feminine. Well, Fenster is neuter.
Does the feelings exist? I want to know. In order to find out, the easy way is to create an AI to guess the grammatical genders of nouns with the only information of character sequences. For example, can an AI predict the gender of the noun Apfel simply based on the character sequence of “A”, “p”, “f”, “e”, “l”?
There are previous attempts to do that with simple machine learning tricks. For example, this blog post describes a Naive Bayes model with 73.3% accuracy. The problem with the approach is such model need to extract the features manually. I was curious why no one updates it with newer techniques such as deep learning.
Implementation
The first step, of course, is to collect labelled data. I scraped a lot of German nouns with their associated gender. The first source is the Wikitionary. It has over 30,000 nouns. After I created the first two prototypes of the AI model, I discover there is actually an attempt to train an AI model to do that. It has a dataset with even more nouns. So, I combined the two sources together to obain a dataset of 329,876 nouns. I have doubt about this dataset because I can imagine it contains a lot of compound nouns such as: Schweinefleischetikettierungsüberwachungsaufgabenübertragungsgesetz. But anyway, I have a big dataset. What’s next?
The second step is to train a deep learning model. The problem I need to solve is hardly new, just a typical sequence prediction problem. There are zillion of examples on the web about how to train a deep learning model to do just that. The Python library Keras includes lots of examples and many of them are about sequence prediction. If you are lazy, likes me, you can just copy and paste those codes, modify the model to cater for the dimensionality of your data, and train.
I have a love-and-hate relationship with Python, but well, Python is the so-called “language of deep learning”. My solution is to use the R bindings to Keras. I can have the best of both worlds: using R to do data manipulation and Python (binded to R) to create deep learning model.
Building a deep learning model is really easy with the R bindings. These are the code for my model.
model %>%
layer_embedding(input_dim = 66, output_dim = 128) %>%
layer_lstm(units = 96, dropout = 0.05, recurrent_dropout = 0.05, return_sequence = TRUE) %>%
layer_lstm(units = 64, dropout = 0.05, recurrent_dropout = 0.05) %>%
layer_dense(units = 3, activation = 'sigmoid') %>%
compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = c('accuracy')) %>%
fit(X, y, batch_size = 300, epochs = 30, validation_split = 0.20)
The difficult part, however, is how to transform the data so that it can be fitted into such model.
The model of choice, is Long Short Term Memory (LSTM) network. In simple terms, this model can generalize memory states based on temporal sequences and utilize those memory states for prediction. For example, a sequence of “k”, “e”, “i”, “t” might constitute a memory state and be useful for prediction.
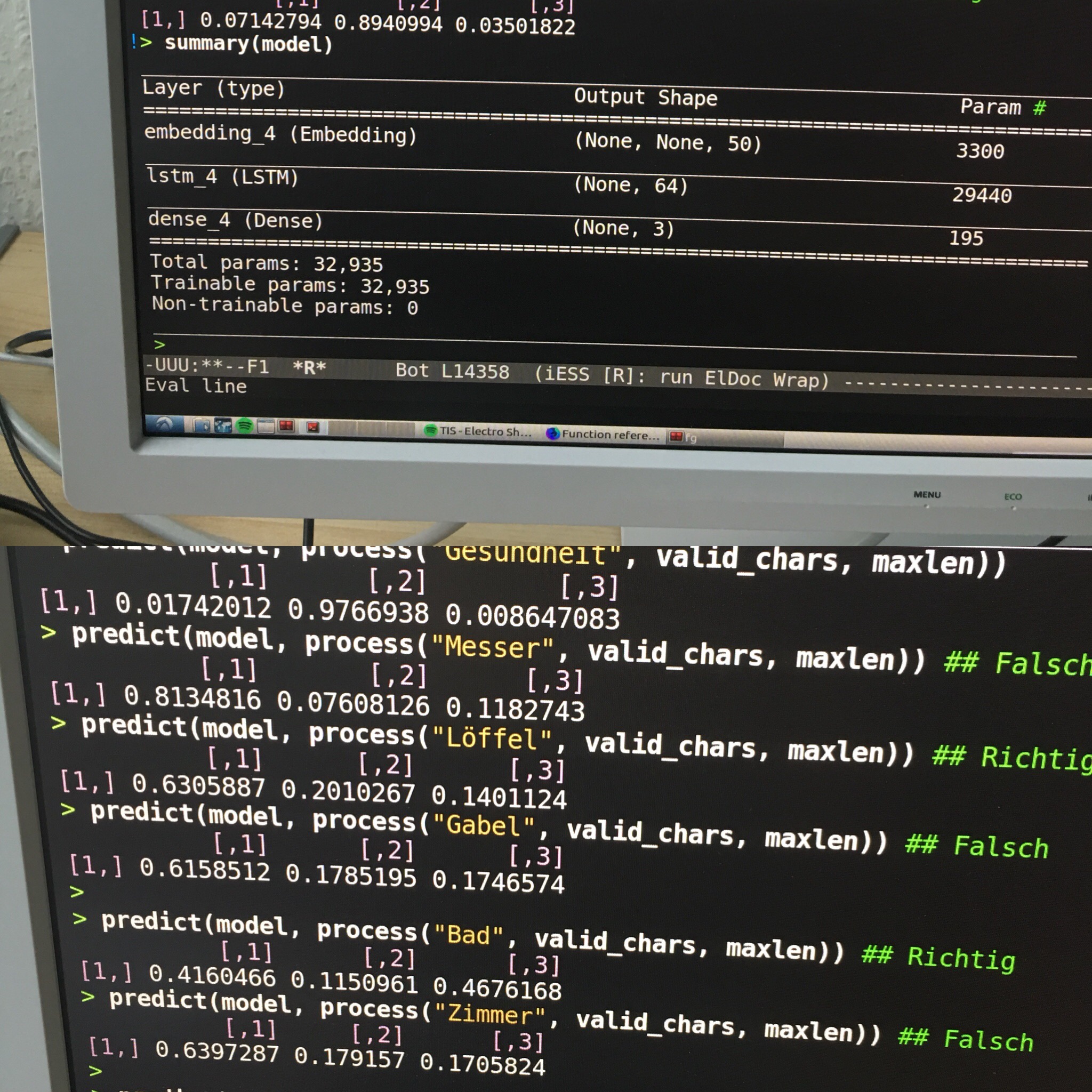
A previous 2-layer LSTM model has achieved 96.2% accuracy. My final model, with an additional embedding layer, can get a little big higher of 97.8%. Does it really work that great? Let’s validate it with some soft balls and hard balls.
Validation
Soft balls
- Gesundheit / Health - 99.6% Feminine (Correct)
- Zeitung / Newspaper - 99.78% Feminine (Correct)
- Mädchen / Girl - 99.36% Neuter (Correct, yes, girl is neuter.)
- Terrorismus / Terrorism - 99.72% Masculine (Correct)
Maybe hard balls
- Tasche / Bag - 82% Feminine (Correct)
- Maschine / Machine - 81.29% Feminine (Correct)
- Schlüssel / Key - 99.53% Masculine (Correct)
- Zimmer / Room - 92.64% Neuter (Correct)
- Rock / Skirt - 65.84% Masculine (Correct, yes, Skirt is masculine.)
Hard balls
- Euro / Euro - 47.39% Masculine, 38.00% Neuter (Correct)
- Schüssel / Bowl - 81.03% Masculine, 21.91% Feminine (Wrong)
- Messer / Knife - 68.42% Masculine, 19.46% Neuter (Wrong)
- Löffel / Spoon - 98.48% Masculine (Correct)
- Gabel / Fork - 75.02% Feminine, 15.10% Masculine (Correct)
- Bad / Bathroom - 55.61% Neuter, 24.72% Masculine (Correct)
- Resturant / Resturant - 64.90% Masculine, 37.30% Neuter (Wrong)
- Fenster / Window - 75.75% Masculine (Wrong)
- Vatter / Father - 94.29% Masculine (Correct)
- Mutter / Mother - 74.81% Feminine (Correct)
- Bruder / Brother - 78.62% Masculine (Correct)
- Schwester / Sister - 90.98% Feminine (Correct)
- Krankenschwester / Nurse [Female] - 99.59% Feminine (Correct)
- Krankenpfleger / Nurse [Male] - 99.96% Masculine (Correct)
- Artz / Physician [Male] - 96.99% Masculine (Correct)
- Ärztin / Physician [Female] - 98.69% Feminine (Correct)
- Mond / Moon - 60.11% Masculine (Correct)
- Schnee / Snow - 87.10% Masculine (Correct)
- Sonne / Sun - 77.90% Feminine (Correct)
- Sonn / Son - 77.59% Masculine (Correct)
- Mississippi / Mississippi - 88.11% Masculine (Correct)
- Donau / Danube - 48.82% Masculine, 44.90% Neuter (Wrong)
- Porsche / Porsche - 71.28% Feminine, 23.83% Masculine (Wrong)
- Name / Name - 44.01% Feminine, 40.03% Masculine (Wrong)
- Käse / Cheese - 73.43% Feminine, 29.92% Masculine (Wrong)
- Süden / South - 85.60% Neuter (Wrong)
- Nickel / Nickel - 81.03% Masculine (Wrong)
- Silber / Silver - 47.32% Masculine, 18.97% Feminline (Wrong)
The model can get most of them right. There are some very tricky nouns. From this analysis, we can conclude that those nouns are really difficult, such as Messer (Neuter), Schüssel (Feminine), Resturant (Neuter) and Fenster (Neuter). The model also tends to overestimate the influence of -e ending as feminine noun, as in the cases of Name and Käse. There are also rules based on word meanings which the model cannot understand. For example, names of rivers in Germany are all feminine but those in other countries are mostly masculine (Donau versus Mississipi), car producers are masculine (Porsche), directions are masculine (Süden), metals are neuter (Nickel and Silber), etc. Meaning-based rules are not common but words associated with these rules are commonly used.
The LSTM model can also be used to answer some unresolved questions. The silly question that always being asked in German classes is the grammatical gender of Nutella. Even Germans can’t decide! According to my LSTM model, it says 51.59% being die Nutella. For Joghurt, it says 76.40% der Joghurt. I am pretty sure our dataset is based on German German, not Swiss or Austrian German.
Summary
In summary, this analysis found that the rules govern the gender of German nouns can be generalized into a deep learning model. The model works well with compound words. The validation of such model revealed nouns which are truly difficult to determine their genders.
Bonus
Apart from sequence prediction, one can also do sequence creation with an LSTM model. I can ask the model to “dream” some randomly generated German-sounding nouns based on the spellings of the existing 329,876 nouns. I can adjust the “dreaminess” based on a hyperparameter called temperature. With a reasonable temperature setting, these are some nouns dreamed by the AI:
Selbstwarenken, Sexualandel, Mitter, Gestand, Gesamik, Herzstrationsschlag, Hauptster, Panapie, Melonessel, Kunstellingsstellung, Transchaftsschwein, Parapfen, Einzelle, Inform, Flecke, Finante, Schleppenstellung, Hodismus, Amente, Bestabilität, Haustrieb, Werkschen, Grenzeichskenraum, Erdbeinkontrolle, Nachtbaum, Siebel, Stacherung, Polyche, Erganismus, Einspeziehung, Homologe, Laufwand, Blauchmelze, Erdausgabe, Straßenarbe, Fernschaft, Konzereiter, Abrief, Halbbaum, Kreise, Gelbst, Haushaltsport, Hausel, Stache, Rotbaum, Kommung, Schwanzahl, Freihe, Geldkatzen
I really like some of them, such as Werkschen (small works?), Nachtbaum / Halbbaum (night tree / half tree?), Erdausgabe (Earth output?) and of couse my favorite, Geldkatzen (Money cats).
Final remarks: It is very painful to train deep learning models in a machine without a decent GPU (such as my 2015 Macbook Air)! Mac is not a good platform to train those models.