chainsawriot
Home | About | ArchiveWeek 5: Forecasting the future of this blog using time series analysis

I have a pretty scary confession to make. Actually, I have not learned time series in a systematic way. It is hard to imagine a person with an Epidemiology and Biostatistics master degree says something like this, but this is the case. I don’t know why my master education does not offer time series analysis even up to this day. Of course, my PhD education has almost no course work and therefore my systematic understanding of statistics has not been improved after my PhD. I am ashamed for my lack of knowledge in time series analysis. The reason why I say this confession is scary, is that I have published two papers with time series analysis and the core analytic tool in my PhD thesis is actually time series analysis. Looking back, those papers had been written in a way, similar to the way a person driving a car without any knowledge about the car. To me, this lack of knowledge is almost like a guilt.
I always hope that the above discourse is just a symptom of my impostor syndrome. However, it is really a big problem. I think I have two skill sets developed over the years: social network analysis and text analysis. I don’t think I have the chance to use my social network analysis knowledge at the moment. Time series analysis is now creep into much of my current research. Every time I do time series analysis, I need to google a lot. Although I don’t mind the googling, I don’t speak the language of time series analysis. For example, I was not be able to understand the ARIMA model, because I did not know what stationery, white noise, differencing, integration etc are.
I always want to brush up my skill again. Filling this knowledge gap in time series analysis is always on top of my agenda. But I have made a lot of excuses not to execute such a plan. Probably due to my chronic procrastination. During the winter break, my wife was on her vacation abroad and I had a lot of time to do a lot of self-reflections and I have decided to take control of my life again. I have made a lot of decisions 1. Among one of those decisions, I have decided to pay for the courses provided by Datacamp. In particular, I am finishing all of the time series courses.
The best way to learn something is to “learn out loud” 2. So I think I should apply what I’ve learned so far to forecast the future of this blog.
So, I have scraped my own blog using rvest and touched it a bit using dplyr. The number of posts I wrote monthly since 2001 Oct is like this:
require(rvest)
require(tidyverse)
require(lubridate)
require(astsa)
blog_index <- read_html('http://chainsawriot.com')
blog_index %>% html_nodes('span.post-meta') %>% html_text -> date_stamp
data_frame(date_stamp) %>% mutate(date = mdy(date_stamp)) %>% mutate(year = year(date), month = month(date)) %>% group_by(year, month) %>% tally -> dirty_monthly_nposts
### QUICK AND DIRTY
data_frame(year = c(2001, 2001, 2001, sort(rep(2002:2018, 12))), month = c(10, 11, 12, rep(1:12, 17))) %>% left_join(dirty_monthly_nposts) %>% mutate(n = replace_na(n, 0)) -> monthly_nposts
nposts_ts <- ts(monthly_nposts$n, frequency = 12, start = c(2001, 10))
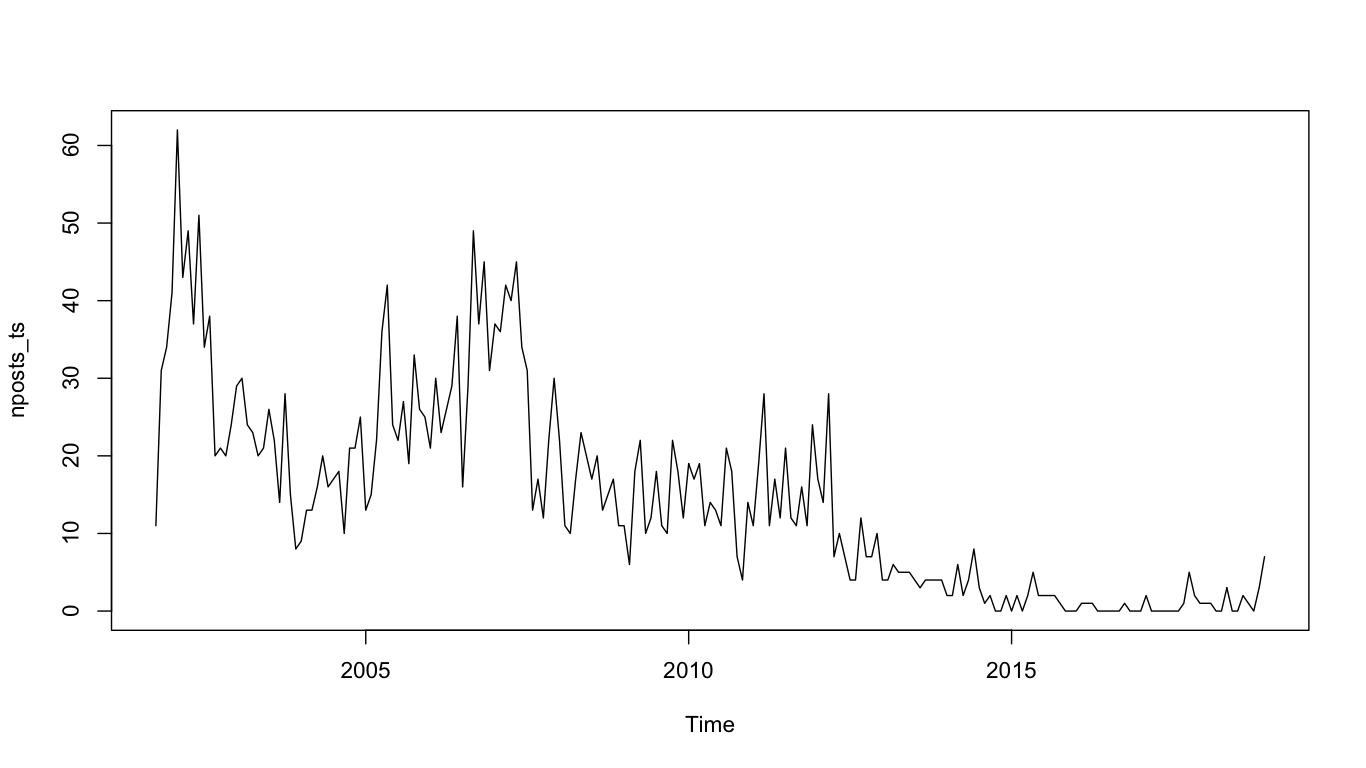
In order to do a forecast, I need to know how to make this time series white (as in white noise. The time series should looks randomly up and down). There is obviously a downward trend here. It is a good idea to detrend this time series by differencing it. It means the current value is minus by the previous value. The differenced time series looks like this.
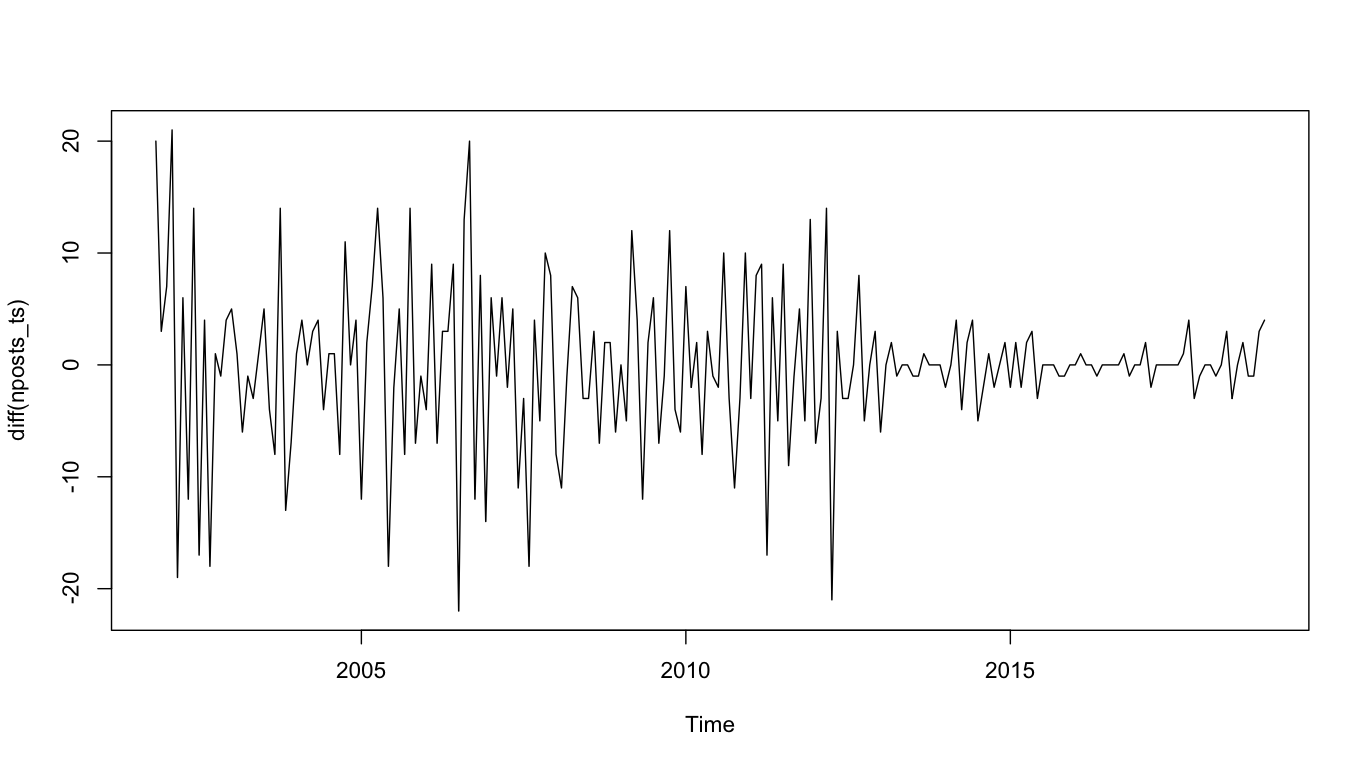
It looks much better. A simple ARIMA model has three parameters: p (autoregressive), d (differencing) and q (moving average). The ARIMA structure is represented by the three parameters, e.g. (1, 1, 0). The goal here is to find out this ARIMA structure. Now, it seems to me that differencing is helpful here. So d should 1. But still, I need to look for other parameters. It is a good idea to plot both ACF and PACF together.

Interpreting the two charts is difficult because it’s like palm reading 3. But the ACF looks cut-off at 1 and PACF looks tail-off at 1. MA model seems to be a better choice. So our final ARIMA structure should be (0, 1, 1).
acf2(diff(nposts_ts))
acf2(diff(nposts_ts), max.lag = 60)
sarima(nposts_ts, p = 0, d = 1, q = 1)
sarima.for(nposts_ts, p = 0, d = 1, q = 1, n.ahead = 12)
By fitting an ARIMA(0, 1, 1) model to the time series and then using such model to forecast this blog in 2019, it seems that I will still write some blog posts in this year. But in general, my predicted productivity is in a downward trend.
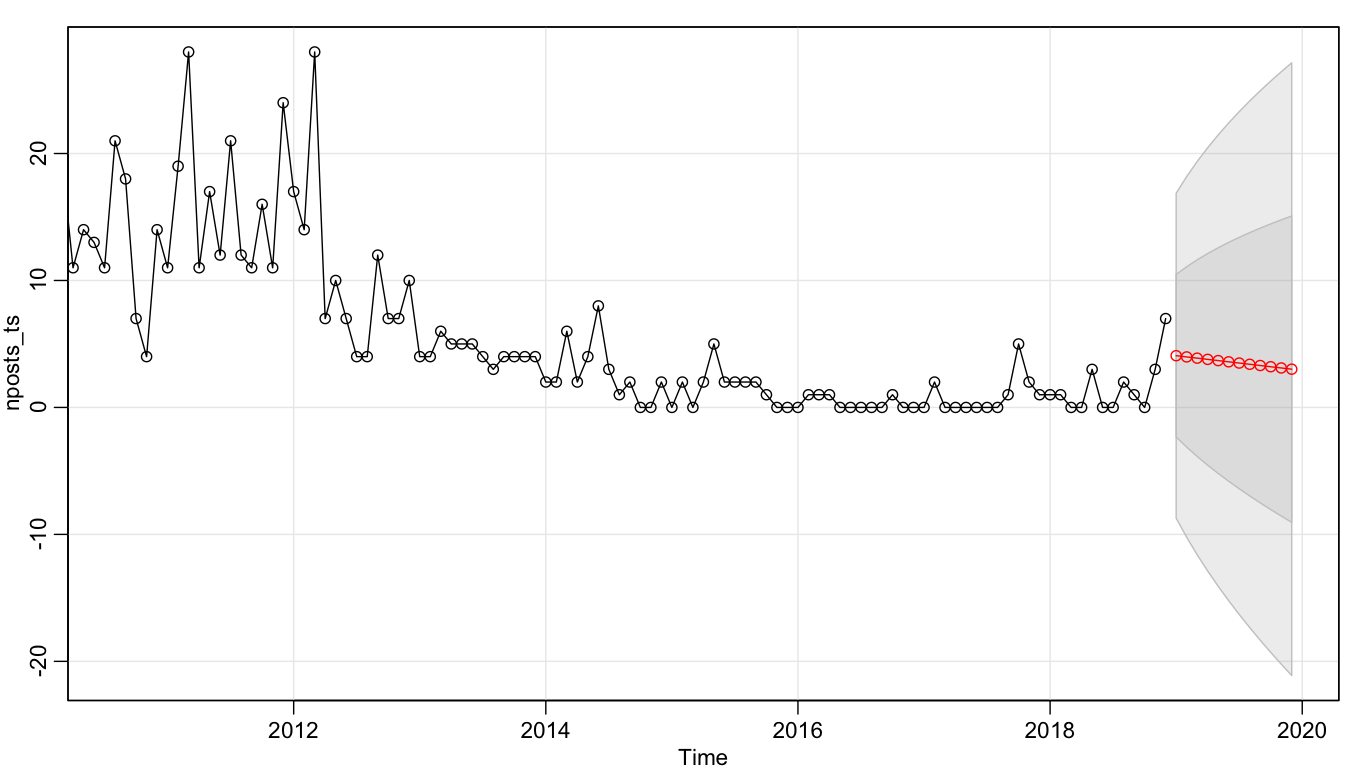
I hope it is not the case. If I can keep up the drive of writing one technical post per week, I think I could somehow break this prediction. But who knows? Bitte drücken Sie mir die Daumen.
5 down, 47 to go.